Trust at scale: Auto-evaluation for high-stakes LLM accuracy
Elicit’s mission is to scale up good reasoning. Large language models (LLMs) are currently the most promising technology to achieve this goal, and we use them extensively to help our users search and analyze the scientific literature.
But LLMs are known for their unreliability: they often misunderstand instructions, fail to find the right answer, or make up plausible-sounding “hallucinations.” In many cases, especially in rigor-demanding domains like science or medicine, human judgment of the output is therefore necessary. Unfortunately this means that most of the scaling benefits are lost: good reasoning is still limited by scarce human intelligence.
To succeed, then, any AI company in a high-stakes field must also scale trust. We need users to know that Elicit’s answers are trustworthy without double-checking them every time, which means we must measure and improve their accuracy in ways that are compatible with our goal of scaling reasoning. For this, we need scalable and trustable evaluation.
The scale–trust–flexibility tradeoff
To scale trustworthy answers, we need to get human feedback on all tasks given to Elicit’s AI. The crudest way to do so is to ship the product to customers, then course-correct based on suggestions and surfaced problems. However, this is a slow and imprecise feedback loop, so we also perform in-house evaluations (often shortened to “evals”) before releasing new changes.
These evaluations exist on a spectrum between scale and trust, to which we’ll add a third dimension called flexibility:
- Scale is speed, cost, and ease of running the eval after updating the task, allowing quick iteration when developing Elicit.
- Trust is accuracy and alignment of eval with task goals, with the objective of holding Elicit to an extremely high quality bar.
- Flexibility means adaptability of the eval to custom tasks, e.g. applicability to a wide range of possible questions.
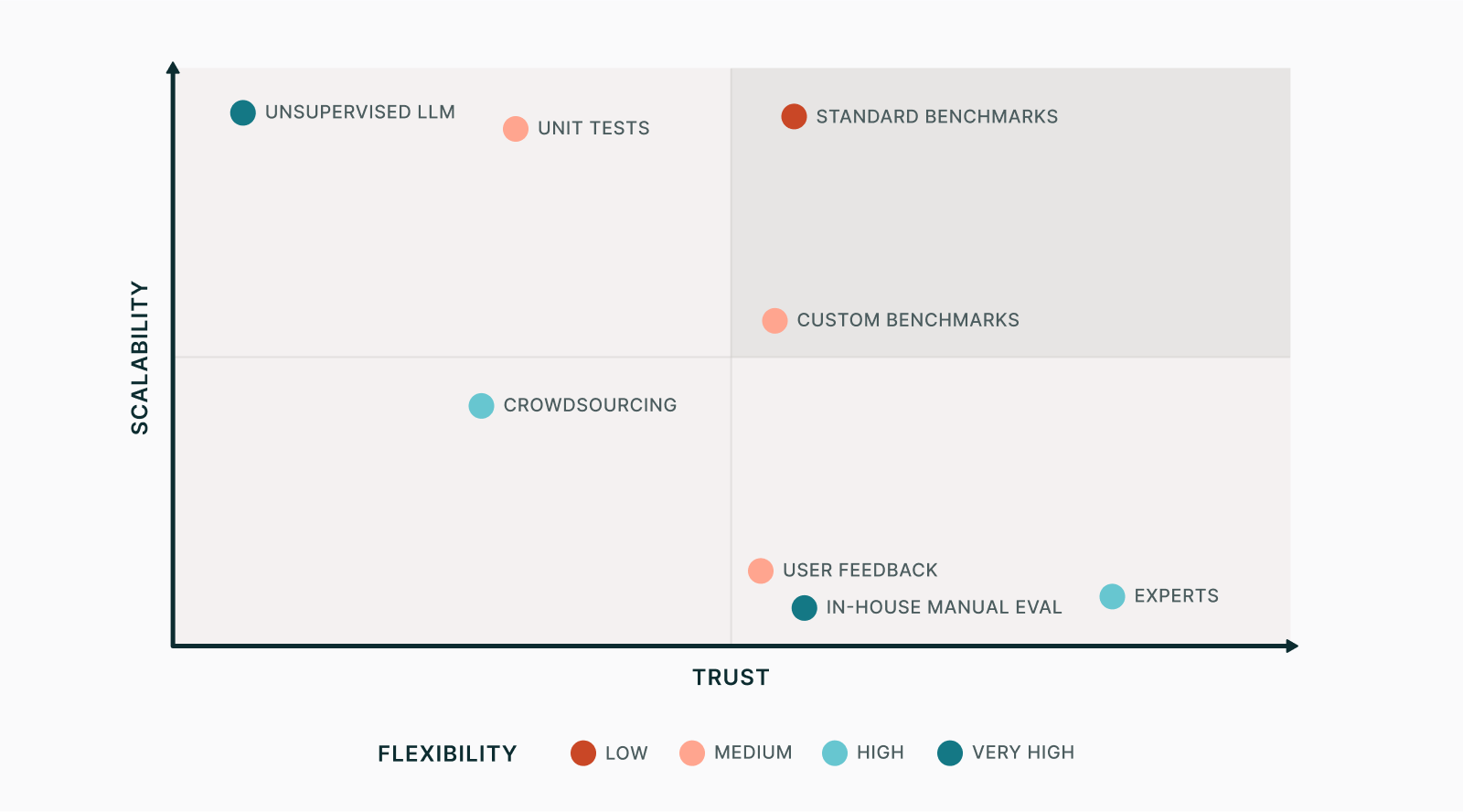
Trust at the small scale
When we create a new feature in Elicit, we always manually vet the outputs. For example, if we want to know how well Elicit can extract a specific piece of information from a scientific paper, we can consult the paper and validate the Elicit’s answer. Such in-house manual eval is relatively trustable, since we know what we expect the feature to do. But to get a good evaluation measure, we need to look at many answers, and repeat the process every time we change something, which quickly becomes time-consuming. This is not scalable.
There is also the problem that, for highly specialized tasks, trust is limited by our local expertise. Features that deal with complicated scientific literature can be difficult for us to evaluate. One idea to improve on the trust dimension is to hire domain experts. However, this is even less scalable, since experts can be expensive and difficult to find.
What doesn’t work to scale up trust
- On the surface, crowdsourcing seems like a promising approach to scale human evaluation. For example, Elicit used to use Surge AI, which let us define an evaluation task and send it to dozens of contractors. This is cheaper and faster than experts, but came at a steep cost in trust. Defining an eval task and writing instructions for contractors is tricky, and they generally don’t have specialized knowledge. It’s also still too costly to be fully scalable.
- We could also consider standard benchmarks. There is a wide variety of publicly available datasets created by AI researchers for evaluation purposes. For the task of answering questions based on text, which is central to Elicit, examples include SQuAD and QuAC, both of which contain text snippets, questions, and human-determined ground truth answers. Running an evaluation based on existing benchmarks is quick and cheap, and therefore highly scalable; and if they’re well made, their results are trustworthy. The problem, instead, lies in flexibility. Existing benchmarks can’t easily be adapted to the specific tasks that Elicit performs.
- A more flexible alternative is to create our own custom benchmarks. This is a bit less scalable, since evaluation data must be created and maintained, but it can be adapted to specific tasks. However, this is still inherently limited by what’s possible to test for in code.
- The same is true of unit tests, which are simple assertions that can catch problems but can’t fully evaluate a complex task and, while useful, are generally not fully aligned with what we want.
Trust at the superhuman scale
So how can we have an eval in the top-right quadrant of our chart, with high scalability and trust, without sacrificing flexibility?
Until recently that would not have been possible. But evaluation is itself a form of reasoning. So the very LLMs we use to scale reasoning should, at least in theory, be able to help. Like many researchers and companies, we have been exploring the possibility of using LLM-based auto-evals, which can be run at superhuman scales and adapt to even the most complex language tasks.
The obvious objection is that we don’t trust language models by default. How does it help to have an untrustworthy LLM check another untrustworthy LLM? The resulting eval would end up on the far left of the chart.
The answer is that we need to incorporate human input into the evaluation process somehow—but we can be clever about it.
How to trust an auto-eval
To illustrate LLM-based auto-eval, let’s consider one of Elicit’s core tasks: the extraction of specific information from scientific papers.
For example, suppose we want to extract the intervention performed in studies of ashwagandha, a plant used in herbal medicine. In Elicit, it would look like this:
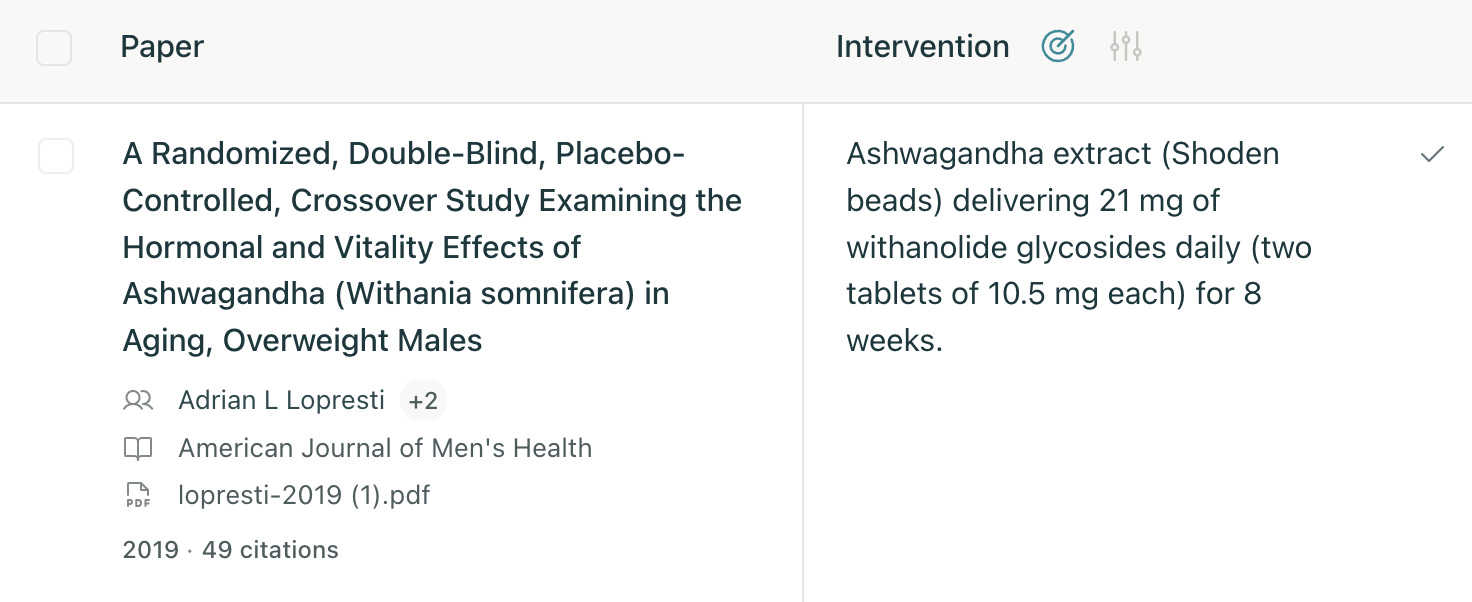
When doing an auto-eval, we reproduce this task internally and then use an LLM to evaluate the results. This means that we need at least the following parts:
- Data that allows us to reconstruct the task in a way that is representative of real usage. In our example, this would be the full text of the Lopresti et al. (2019) paper, together with the definition of the “Intervention” column.
- The code that generates answers in the app from the input data.
- An evaluation criterion, for example “is the answer accurate?”
- An evaluator LLM.
- A prompt in which we insert Elicit’s answer, as well as any other useful information (e.g. the paper text), and ask the LLM to evaluate the answer in terms of the criterion.
In the ashwagandha example, the prompt could look like:
You are tasked to evaluate the ability of a student to answer questions based on papers. Here’s the full text of the paper “A Randomized, Double-Blind, Placebo-Controlled, Crossover Study Examining the Hormonal and Vitality Effects of Ashwagandha (Withania somnifera) in Aging, Overweight Males”:
“Abstract: Ashwagandha (Withania somnifera) is a herb commonly used in Ayurvedic medicine to . . . [Full paper text omitted for brevity]”
The student was asked to identify the intervention in this paper. They answered “Ashwagandha extract (Shoden beads) delivering 21 mg of withanolide glycosides daily (two tablets of 10.5 mg each) for 8 weeks.”
Is this accurate? Say yes or no.
This prompt is a good starting point. But note that beyond the wording of the prompt and the overall design of the evaluation, there isn’t any human oversight. How do we know that the LLM’s “yes” or “no” answer is trustworthy?
Meta-evals
One way of incorporating human input at a point of high leverage is to manually evaluate the eval. At Elicit, we call this process a meta-eval.
The idea of a meta-eval isn’t complicated: it consists of having a human—or several—give their own scores to generated answers, and then calculate agreement with the scores generated by the auto-eval. If agreement is low, for instance because the model says “yes” far more often than a human thinks it should, then the original auto-eval is changed. This could mean updating the evaluator prompt or picking another evaluator model. The process is then repeated. Once the meta-eval is satisfactory, we can assume the auto-eval has reached a sufficient level of quality, and run it on its own with no further human evaluation.
The one downside of meta-eval is that, since it is by definition manual, it is fairly tedious to iterate on: you must re-determine human-machine agreement each time you change it. But if done well, it is the epitome of scaling trust. In less than a day of work, you turn your auto-eval into a trustworthy evaluation pipeline, which in turn allows fast iteration on the tasks that users care about.
Meta-evals can, and arguably should, be done for any type of LLM-based eval. But to reach the highest possible level of trust, they’re not sufficient. The limitation is that the answers are still unmoored to any ground truth. To get the best possible results, we need to add that.
Gold standards
The way we add human-verified ground truth at Elicit is to supply a set of manually verified gold standard answers. Instead of a vague “is this accurate?” criterion, we ask the LLM to determine whether the generated answer and the gold standard are the same. The LLM then gives either a TRUE or FALSE answer. The higher the proportion of TRUE, the higher the actual accuracy in the app.
In other words, we create our own custom benchmark with predefined correct answers. But unlike simple benchmarks with clear, objective answers (like multiple choice questions), the kinds of questions Elicit users ask of scientific papers often allow a range of valid answers, which is why we need a flexible evaluator LLM rather than, say, simple string matching. For example, our gold standard for the intervention question above is:
Ashwagandha extract Withanolide glycosides: 21mg daily for 8 weeks.
This is not identical to the answer currently given by Elicit, which, again, is:
Ashwagandha extract (Shoden beads) delivering 21 mg of withanolide glycosides daily (two tablets of 10.5 mg each) for 8 weeks.
But they essentially mean the same thing. The mentions of “Shoden beads” and “two tablets of 10.5 mg” are simply extra detail. We want our evaluator LLM to say TRUE, so we make sure our prompt asks for the right degree of stringency, for instance by asking whether the core meaning is the same rather than the entire answer.
This type of auto-eval works well because it is much easier to validate a hypothesis, like “answer A and answer B mean the same thing,” than to simply answer the question “is answer A accurate?” This is one way in which LLMs allow us to scale trust. If we have high quality gold standards—admittedly a big “if”—then we can reach trust levels roughly on par with hired expertise.
Gold standards are particularly useful for tasks like data extraction where we have access to the ground truth answer, which in this case can be obtained from manual extraction from real papers. We have been building a dataset of hundreds of verified answers to many of the predefined columns in Elicit, like “Intervention” or “Region,” for a variety of papers. We use the dataset whenever we need to run the eval for data extraction after, for instance, switching to a new model or trying a new data extraction process.
The overall level of agreement of Elicit’s answers to these gold standards provides us with our main accuracy metric, the one we work the most on increasing. Our auto-eval has proved invaluable for this.
But this type of auto-eval comes with downsides: creating and maintaining gold standards is time-consuming, and doesn’t work for tasks where there isn’t clearly one right answer. For example, when evaluating Elicit’s capacity to generate summaries of paper abstracts, we don’t want to constrain the output to specific pieces of information: we just want a general measure of whether the summary accurately reflects the abstract and is relevant to the user query. Therefore, gold-standard-based eval is a bit less flexible and scalable than general meta-evaluated LLMs.
Putting it together, we can update our figure with human-vetted LLM-based evals: with meta-evaluation but without gold standard, and meta-evaluated with gold standards.
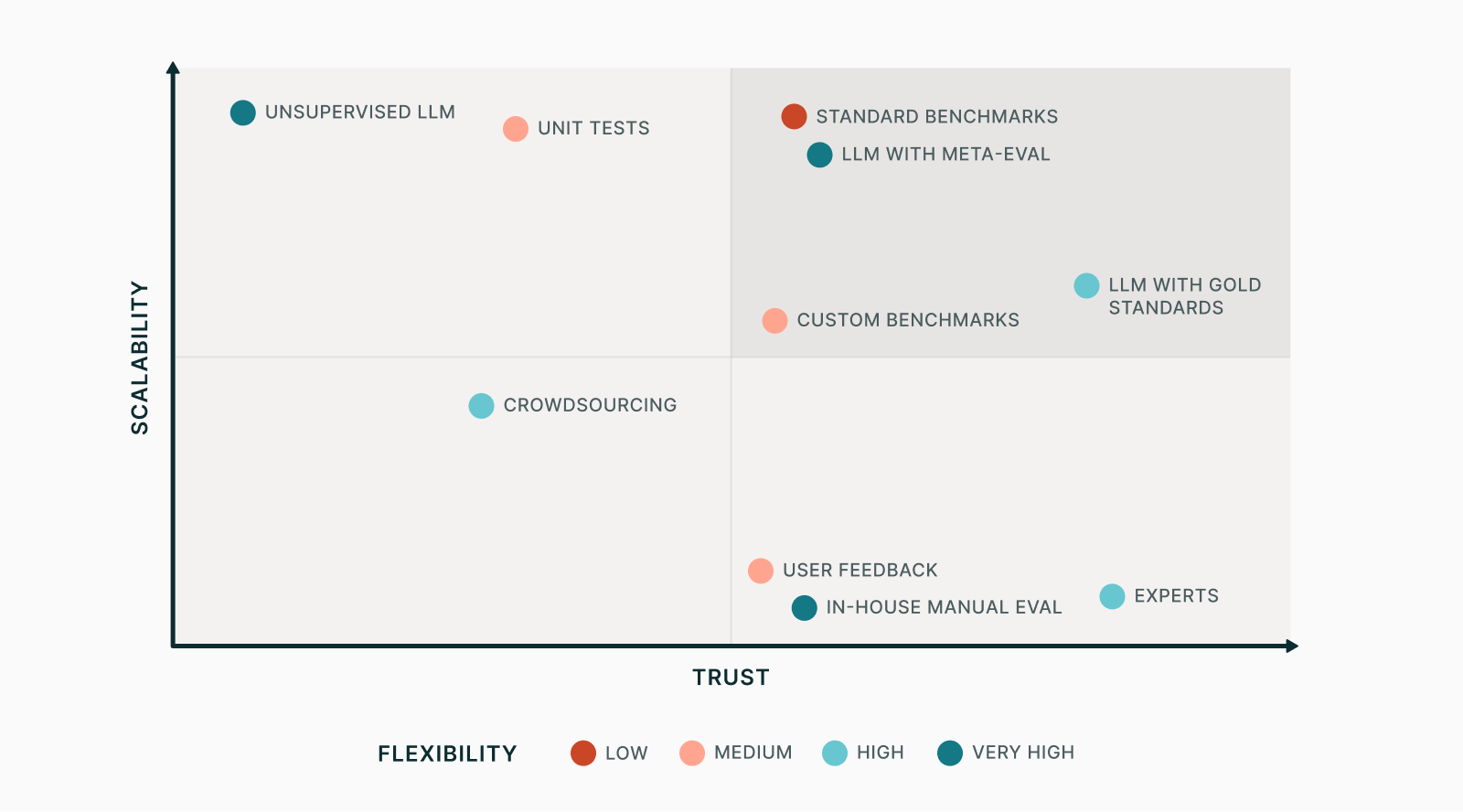
There may be other ways to reach an enviable spot in the three-way tradeoff. Recently we had an experimental collaboration with Atla, who train evaluator models to be attuned to a specific evaluation task and therefore reach even higher trust, at a cost in flexibility. So far we have found that our own LLM-based evals are sufficiently reliable, so we haven't felt the need to use custom models, but we think this is a promising approach.
Challenges of LLM-based eval
LLM-based auto-evals are still a young technique, and anyone using it is bound to bump into new challenges. Here are a few things we found as we have been implementing and running our evals.
- Choice of evaluator model. When setting up an eval, it usually makes sense to use whichever LLM is the most powerful you have access to; an eval won’t generally be run often enough to make cost a huge issue. However, there’s evidence that LLMs used for evaluations favor their own generations. We have occasionally found that we get more trustworthy results if we evaluate an OpenAI model using one by Anthropic, or vice-versa, rather than having both models be from the same provider.
- Meta-eval stability. Once a meta-eval is complete and an eval is considered trustworthy, you can’t change the evaluator model or prompt without having to re-do the meta-eval. If you do, it’ll also be less meaningful to compare with past eval runs. Since meta-eval isn’t usually too labor-intensive, it’s not necessarily a major problem, but it does mean that eval design choices tend to be “sticky.” We’re still using older versions of GPT-4 for our extraction evaluation, for example.
- Writing eval prompts. As with any kind of prompt engineering, there’s an art to this. Chain-of-thought tends to work well, as does prompting the model with giving actual evidence before giving a score.

- Writing (and correcting) gold standards. For a task where the ground truth is found in complicated scientific papers, this can be extremely time consuming! We spent considerable time creating examples from various sources and then fixing the inevitable mistakes that we found when looking at detailed eval results. We call them gold standards, but they aren’t always golden.
- Strictness of fuzzy comparisons. It’s tricky to determine how well an answer matches a gold standard. We have experimented with allowing varying levels of strictness depending on the type of question: for a number-based question like age or duration, the prompt asks the evaluator to make sure the meaning is the same, but a question like “Summary of introduction” uses a more lenient prompt since many possible answers could be acceptable. This is an issue that has long vexed us, but we’re happy to report that we’ve made serious progress recently!
- Binary vs. more complex scores. You can ask an evaluator LLM to give its evaluation in any format. We use a mix of binary (true/false), ternary (true/partial/false) and X/5 scores. Simpler scoring systems are easier to meta-eval, but more fine-grained ones can contain desirable information. For example, when evaluating the occurrence of hallucinations in a summary, it’s useful to distinguish between no hallucination, minor hallucination that doesn’t change the meaning, and major hallucination that can mislead users.
- Eval difficulty. To get a useful signal, you want your eval to be neither too hard or too easy. The best way to achieve this is to use real data from situations where you noticed your functionality wasn’t working perfectly (which is usually when you’ll want to implement an eval, anyway). But it’s possible that over time, due to improving your prompts or using newer LLMs, you’ll need to redesign the eval or create new gold standards.
Conclusion
LLM-based auto-evals offer a nice way out of the tradeoff between scale, trust, and flexibility. Without them, Elicit’s progress at becoming the most accurate tool for scientific literature reviews would be far slower.
But these evals are tricky to get right, and given how young LLM technology is, there’s not a lot of guidance out there. We’re figuring it out as we go. We’re fortunate to have found ways to make it work well for data extraction and other features, but there’s a lot more to do.
If the high-accuracy use of LLMs and the challenge of scaling trust is something that appeals to you, we encourage you to join our team!
Thanks to Adam Wiggins for writing an early draft of this post, to Kevin Cannon for the design of the figures, and to Jungwon Byun, Ben Rachbach, and James Brady for feedback.