How we evaluated Elicit Reports
We recently announced Elicit Reports: fully-automated research overviews for actual researchers, inspired by systematic reviews.
Through external evaluation by researcher specialists, we find that Elicit Reports produce higher quality research overviews and save more time than the other “deep research” tools, including well-known ones like ChatGPT Deep Research, Perplexity Deep Research, and Google Gemini.
This post describes our evaluation methodology and results in detail, covering:
- Evaluation methodology
- Results
- Overall quality & accuracy
- Time savings
- Qualitative impressions
- Elicit uses quality academic sources
- Elicit makes it easy to check citations
- Elicit's methods are more transparent and flexible
- Elicit generates better tables
- How competitors were better
- Limitations
- Further evaluation work
Methodology
We recruited 17 professional researchers with backgrounds in fields such as neuroscience, speech therapy, economics, organizational psychology, information studies, ecology, and engineering. The evaluators were PhD holders and were not active Elicit users at recruitment.
We asked these evaluators to compare Elicit to competitors in their area of expertise, asking research questions of their choosing, such as:
- Medicine: What is the impact of continuous glucose monitors on reducing long-term diabetes complications such as cardiovascular disease, neuropathy, and kidney disease?
- Engineering: What are the comparative energy efficiencies of renewable energy sources for powering large-scale artificial intelligence and machine learning data centers?
- Speech therapy: What is the impact of evidence-based language interventions on academic performance and social communication skills in teenagers with language disorders?
- Economics: What elements are needed to analyze the competitive position of an airline in the oligopolistic aviation market?
They scored and compared reports on both qualitative and quantitative dimensions:
- Overall quality
- How well the reports answered their research question
- Accuracy and support for the most important claims
- How much time they saved vs. manual research
Evaluators compared Elicit against these well-known “deep research” tools:
- ChatGPT (o3-mini-high) with Deep Research
- Perplexity Deep Research
- Google Gemini Advanced, 1.5 Pro with Deep Research
They also compared against lesser-known platforms that our early evaluations surfaced as strong contenders (Undermind, Ai2 Scholar QA). We left out other platforms (GPT-4o, Claude 3.5 Sonnet, Perplexity Pro, Consensus, and Scite) after our early evaluations quickly demonstrated that they did not come close to meeting the needs of researchers.
In all cases, we asked evaluators to use the best paid versions of each research platform and to generate a report roughly equivalent to Elicit’s using the same research question.
Statistical analysis
Most results reported below are averages.
Due to the high cost and overhead of obtaining evaluations from skilled professionals, we obtained modest sample sizes of around 25-30 evaluations for each competitor.
We used the Wilcoxon signed-ranks test to determine statistical significance. All p-values were calculated on direct paired comparisons of Elicit vs. a competitor tool using the same research questions, but we grouped evaluations together in the graphics below for ease of reading.
Results
In total, 17 evaluators evaluated 29 Elicit reports, and 120 reports across competitor tools:
- n=28 for ChatGPT Deep Research
- n=26 for Perplexity Deep Research
- n=11 for Google Gemini
- n=29 for Undermind
- n=26 for Ai2 Scholar QA.
Overall quality
We asked evaluators to give a general rating of each report on a scale of 0 to 10, where 0 was defined as “useless, low quality” and 10 as “very useful, high quality.”
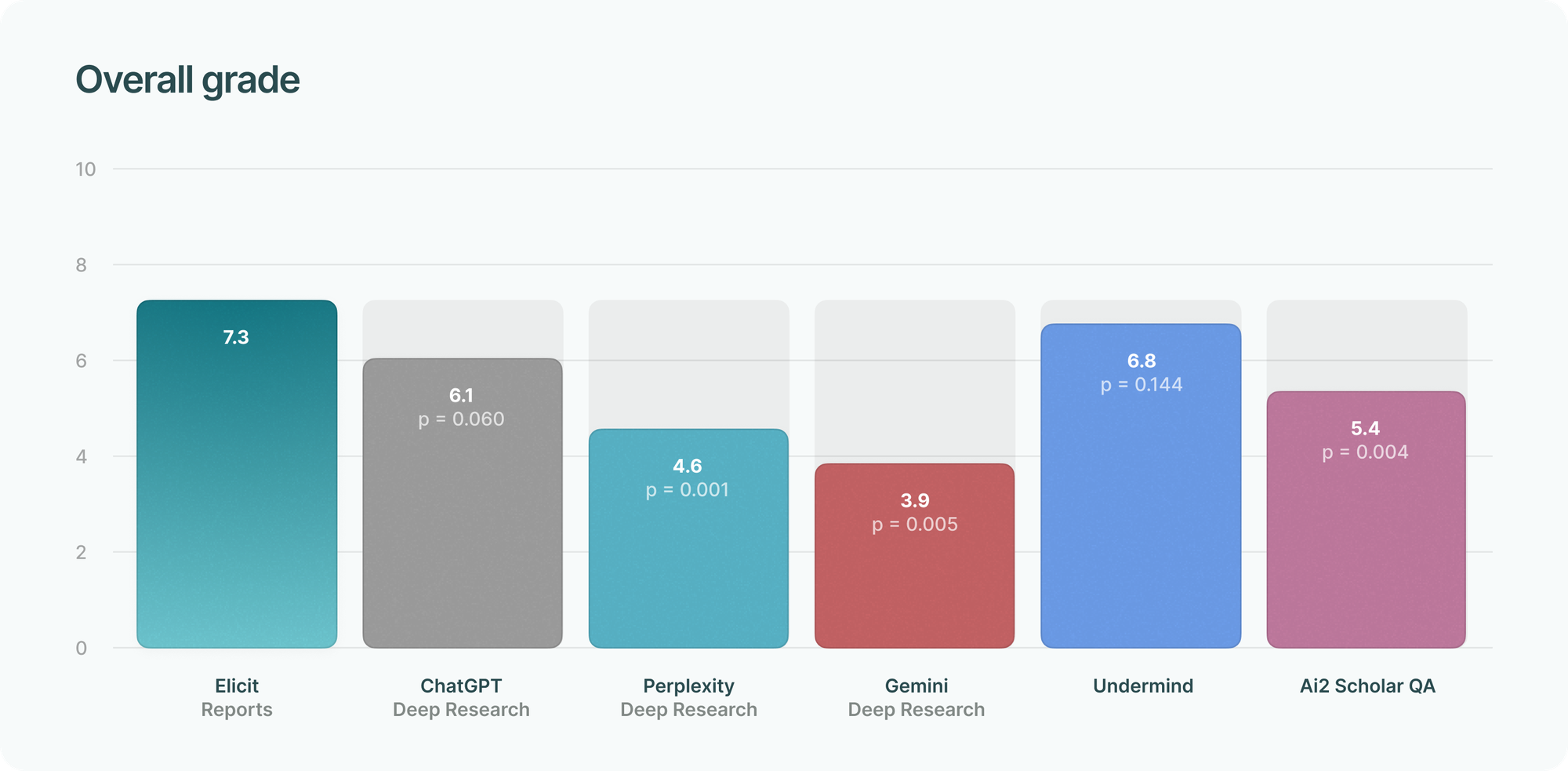
Four Elicit Reports received a perfect grade of 10/10, with feedback such as:
This report was excellent: It spoke to all of the research questions I was hoping to be answered. Particularly impressive was the detailed ‘thematic analysis’ section.
The information was completely on par and displayed in depth data on the various themes I was looking for to answer the question fully.
This is a thorough and systematic examination of the question. In terms of saved labour, the 40 row table comparing studies across characteristics is a huge piece of work. The report is accurate and useful with many interesting insights that I hadn't heard of before. It surfaced some very interesting contemporary scholarship and did an excellent job integrating the findings.
Time savings
We asked evaluators to estimate how many hours the tool would save them when writing a systematic review.
Estimates varied substantially, from 0 to 960 hours, equivalent to 6 months of full-time work at 40 hours/week. Thus the mean estimated time saved is skewed by high values and we report the median instead.
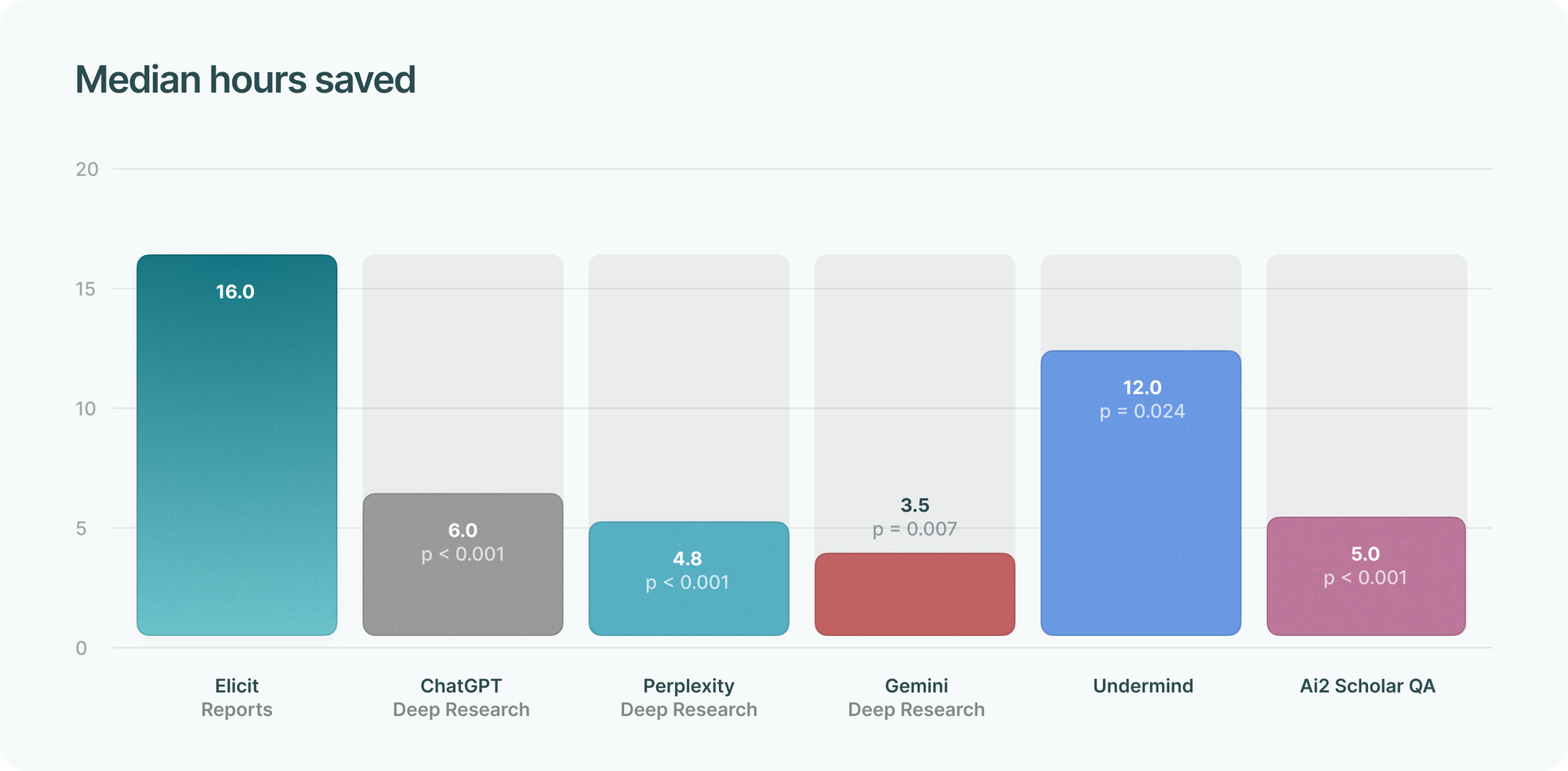
All comparisons were in favor of Elicit and statistically robust. While neither Elicit nor its competitors completely replace a manual systematic review, evaluators noted that Elicit meaningfully saves time getting from a research question to a satisfying report.
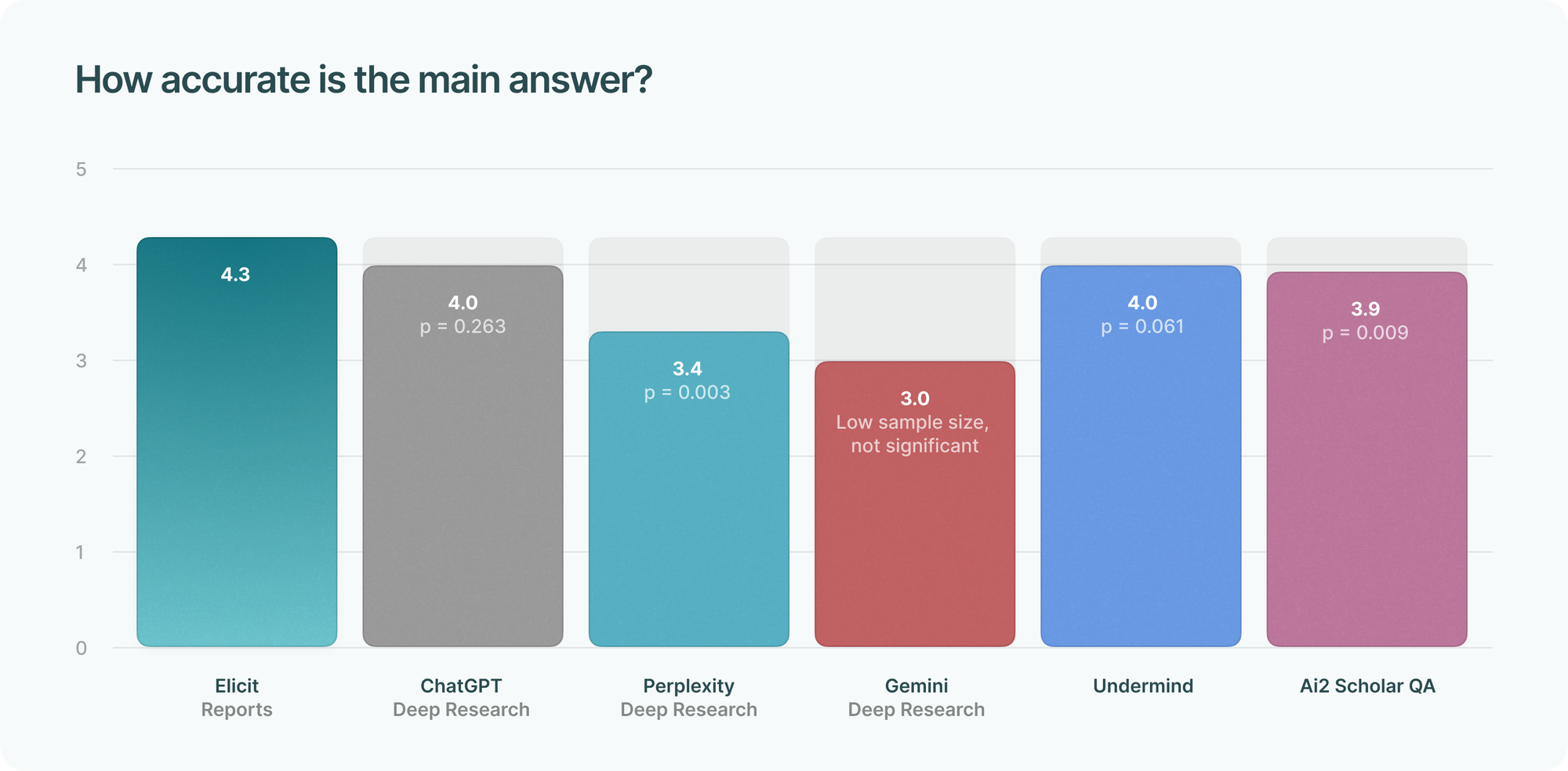
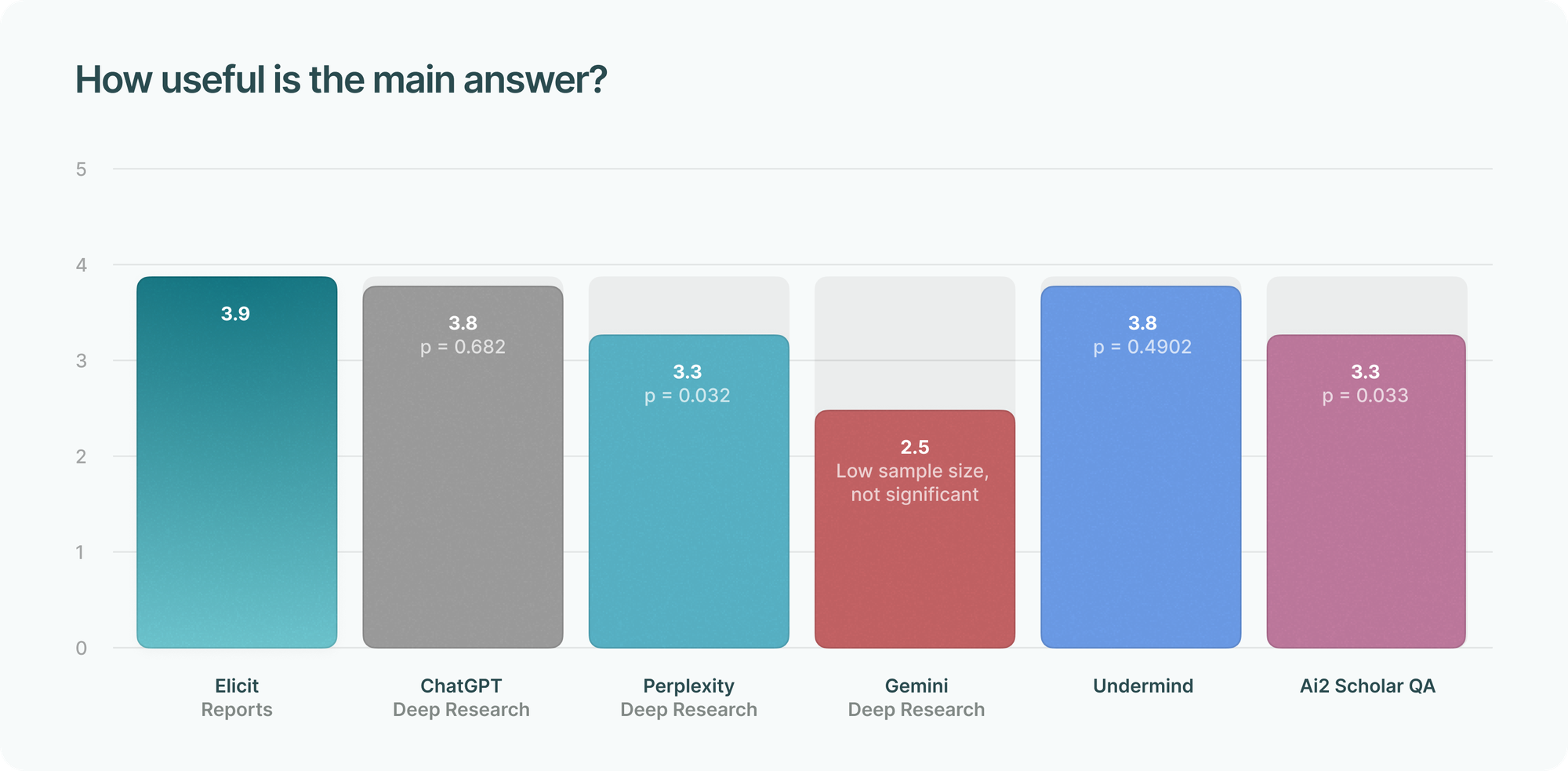
Rating the report’s main answer
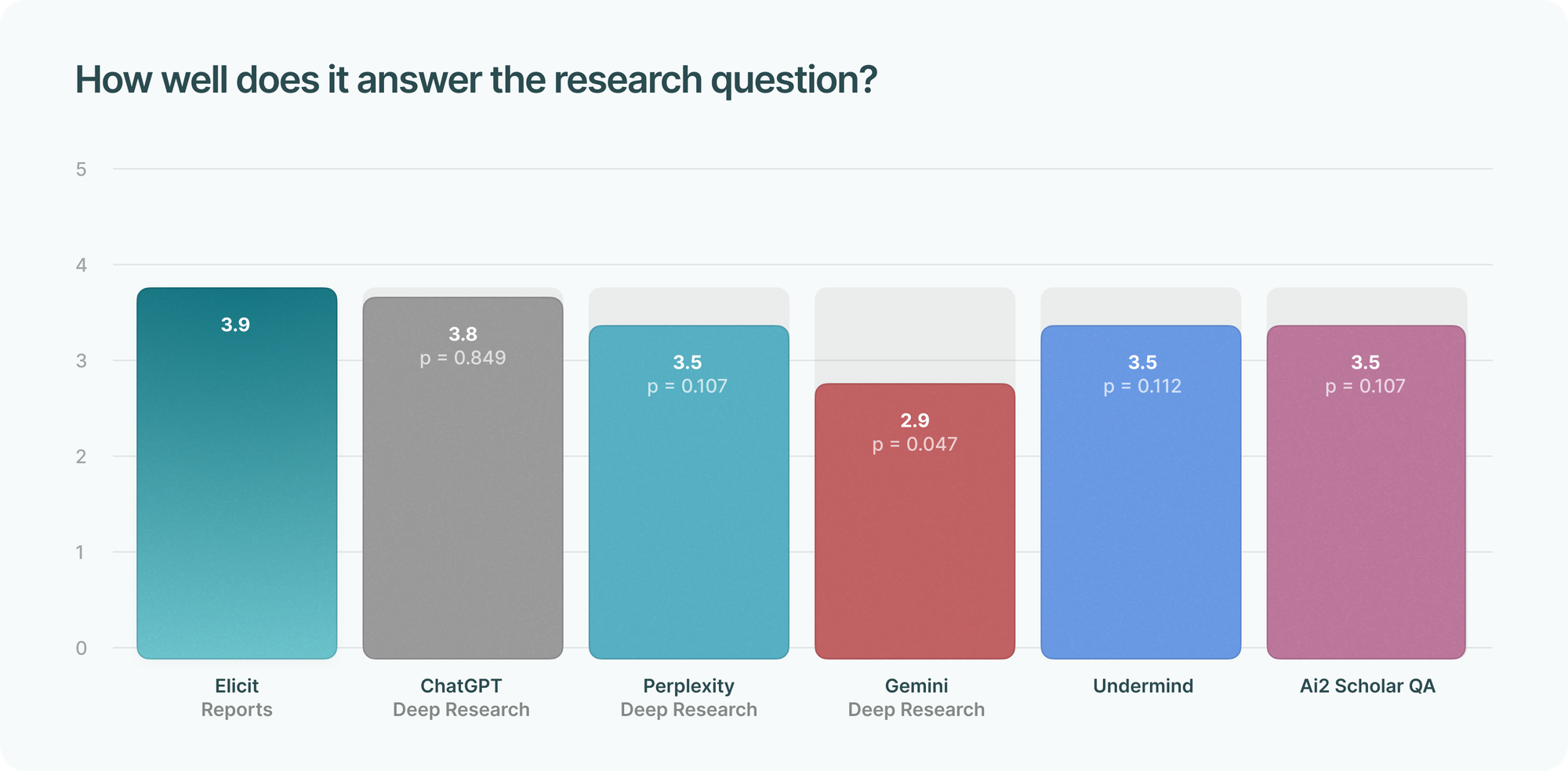
We asked: “How good is the main answer of the report? Look at whatever is the closest to a ‘main answer’” for three metrics: accuracy, usefulness, and how well it answers the research question.
Elicit Reports scored highest across all metrics, though differences are small and generally not statistically significant, especially against ChatGPT Deep Research.
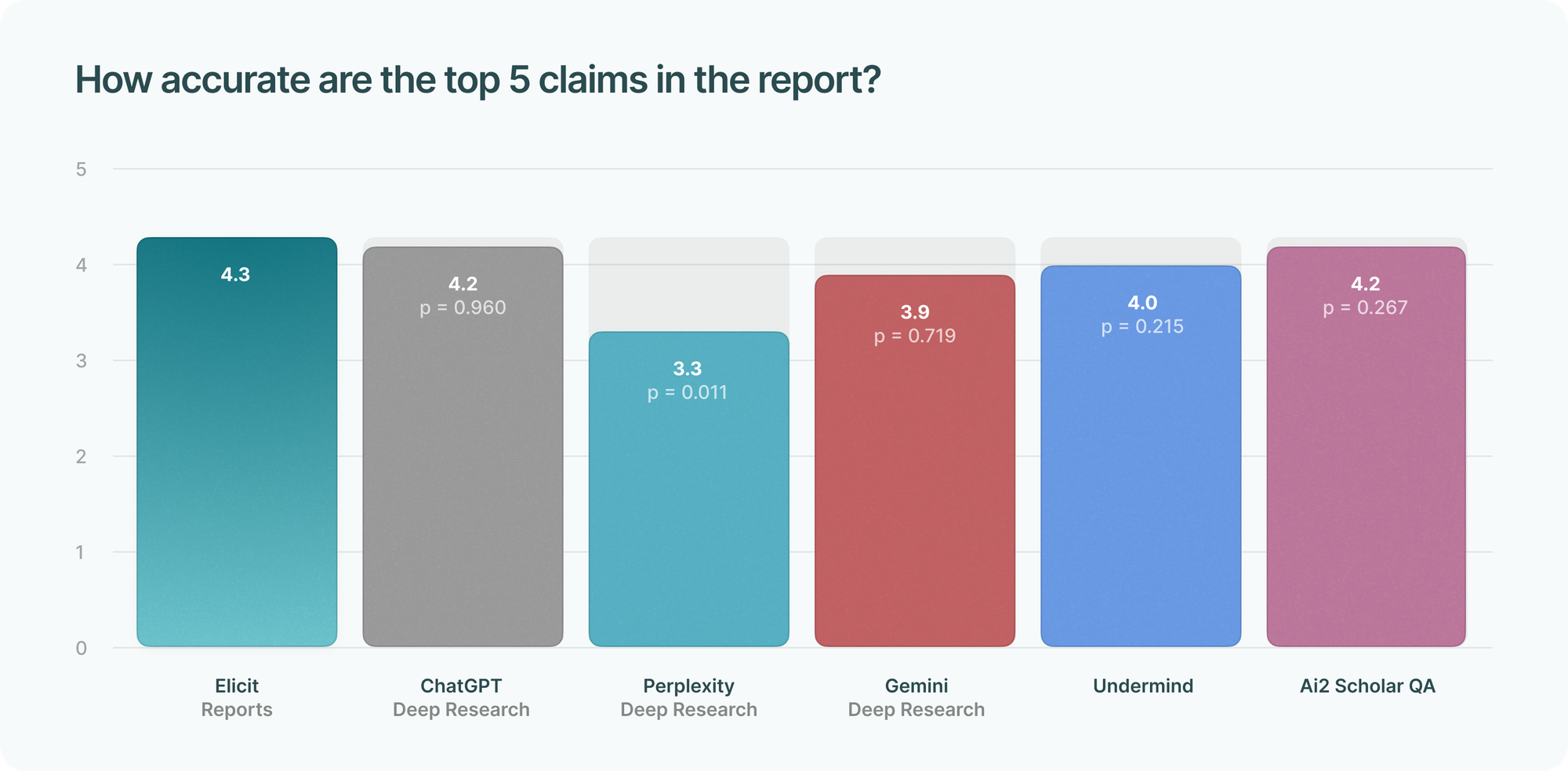
Accuracy and support for top claims
Beyond the main answer, it’s important that each claim in a report is accurate.
Since it is impractical to manually evaluate every claim, we asked evaluators to identify and evaluate the accuracy and citation support of the top 5 most important claims in a report. For example, in a report about evidence-based practices (EBP) in healthcare, an evaluator specified the top 5 claims as:
- “Healthcare organizations with supportive leadership, openness to change, and adequate resources reported better EBP implementation.”
- “Studies frequently mentioned time limitations, resource constraints, and weak research culture as challenges.”
- “Regarding technology, studies found that user-friendly information systems and digital resource access supported EBP implementation.”
- “Common individual barriers included limited literature search skills, skepticism about EBP, and uncertainty about professional roles in implementation.”
- “Practitioners with confidence in their abilities and positive views toward EBP were more likely to implement it.”
The evaluators then graded the accuracy of each claim as follows:
- Correct (1 point)
- Minor errors (0.5 point)
- Major errors (0 point)
We also asked them to evaluate citation support, giving one of the following scores:
- Fully supported (1 point)
- Partially supported (0.5 point)
- Unsupported (0 point)
The scores were then summed to yield a score out of 5 for each report.
We found that several tools performed statistically equivalently as Elicit.
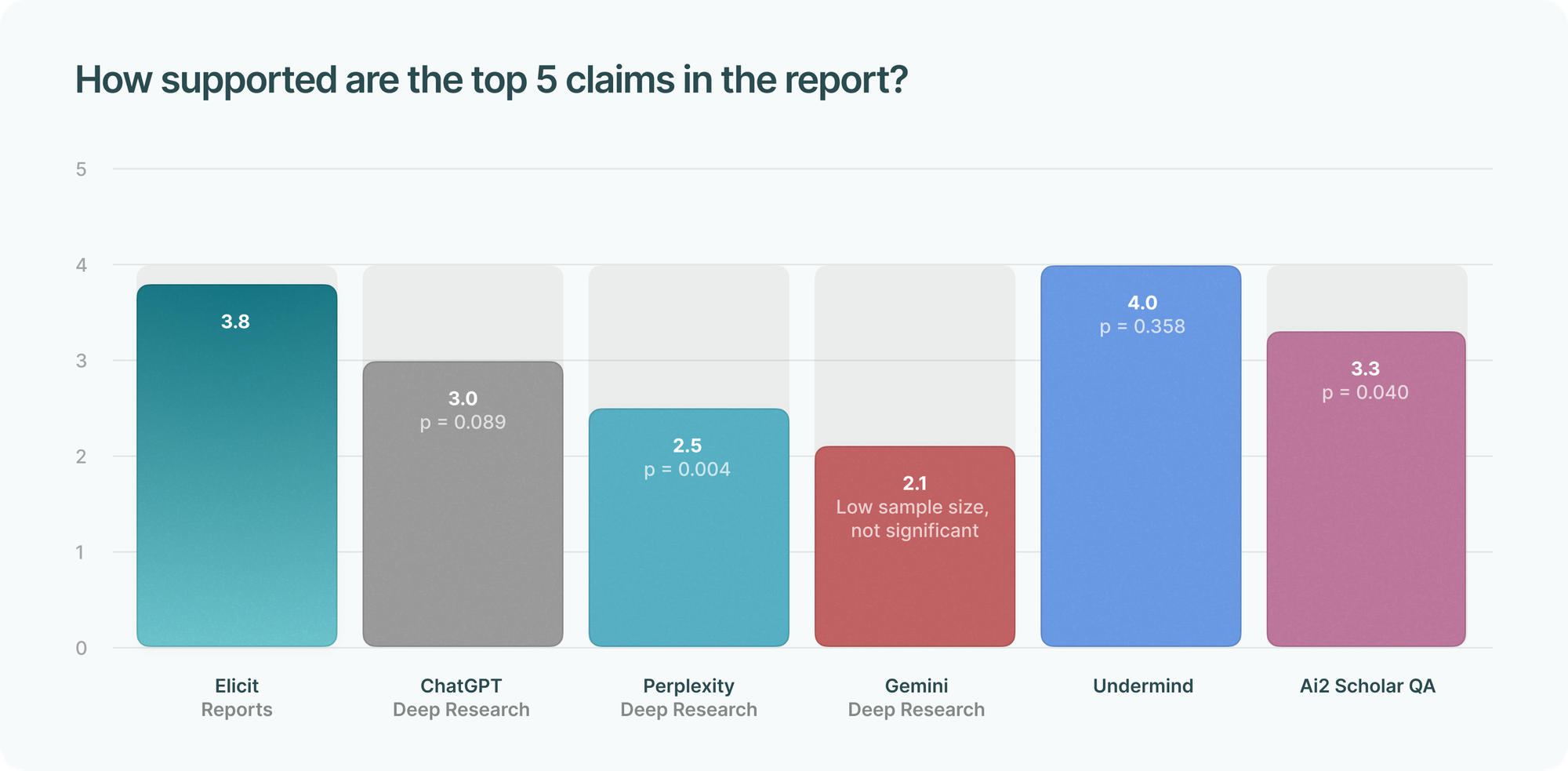
We were surprised that users reported citation support to be similar among tools, since since most evaluated tools do not cite specific passages in text and instead reference entire papers. The evaluators may have considered that linking to entire papers, which is the standard practice in academic writing, is sufficient to consider a claim supported. They did share positive qualitative feedback about this feature (below).
Going forward, we'd like to find ways to evaluate the accuracy and support for all claims in the text. We expect that accuracy in the long-tail is where Elicit shines.
Qualitative impressions
Evaluators shared qualitative feedback in addition to quantitative scores, highlighted below.
Elicit uses quality academic sources
Evaluators noted that Elicit relies on trustworthy academic sources, unlike competitors.
Elicit doesn't include news articles, interviews, blog posts, SEO content farms, and other non-scholarly content.
In Elicit, all information included in a report is derived from a credible, peer-reviewed original publication (ChatGPT includes secondary citations, i.e. general websites such as gettingsmart.com, who base their information on loosely structured position papers by the NIH).
I asked for a scientific literature review, [Gemini] confirmed my ask, but still most of the sources are news articles. Not acceptable for scientific research.
Elicit makes it easy to check citations
Though evaluators did not rate Elicit's citation support as clearly superior, they did appreciate that Elicit cites specific passages in citations.
Elicit shows you the exact quotes from the cited source that are relevant (most of the time).
In-line citations are more readable than ChatGPT. ChatGPT references point only to the subdomain, like pmc.ncbi.nlm.nih.gov, which is functionally useless as a reference to a particular paper.
The citations function works a lot better on Elicit - Perplexity citations take me to a new tab and are just a worse UX.
Supporting quotes are more useful than Undermind's hovercard summaries for references.
Elicit's methods are more transparent and flexible
Evaluators liked that they could understand and modify how Elicit finds, screens, and extracts data. For example, users can add their own papers, override screening decisions, and add or remove extraction questions, and then regenerate their report.
Elicit allows you to bring your own PDFs . . . [It] offers better control over what sources are included or excluded.
The methods section is clear and explicit. This is one of the best things about Elicit reports generally. It shows its reasoning processes in clear, systematic and reproducible output.
Elicit's report is much more transparent and clear in its steps. The ChatGPT output is sophisticated but does not show its working, which from a systematic review point of view is not ideal, especially if it is to be used as the basis for further research.
Elicit generates better tables
Most other research tools do not summarize data in tables that are easy to digest.
Elicit provides a table with cited research and relevant papers at the beginning after the abstract which I find useful.
Elicit organizes data into neat tables (Deep Research generates tables which are too crowded).
How competitors were better
Evaluators rated competitors highly for:
- Background and introduction sections
- The range of papers found
- The ability to ask more questions after report generation
- Discussion of limitations and research gaps
- Features to explore the literature landscape, such as a timeline of publications or an analysis of the main research groups.
We’ll be taking this feedback into account as we further improve Elicit Reports in the coming months.
Limitations
Besides small sample size, our analysis is subject to the following limitations:
- We paid the evaluators, which may have biased their results. However, evaluators (a) did not hesitate to rate competitors more highly at times and (b) justified all their ratings, which leads us to believe that this is not driving results.
- We performed several rounds of evaluations with the same researchers instead of hiring new ones each time. Thus they saw improvement between versions of Elicit Reports, which could also have biased results.
- Though our evaluators are skilled professionals with research experience, their usage of Elicit and competitors may not be fully representative of other users or the full range of capabilities of each tool.
Further evaluation work
Elicit Reports use Elicit Systematic Reviews under the hood, including separate paper search, screening, extraction, and report-writing steps. We evaluated these steps individually, and will share those results soon.
Try Elicit Reports
Fully-automated research overviews, inspired by systematic reviews.
Generate a Report