How we evaluated Elicit Systematic Review
Last month, we introduced Elicit Systematic Review, a new AI workflow that allows researchers to find papers, screen titles and abstracts, and extract data from full-text papers in 80% less time, without compromising accuracy.
Through internal and external evaluations, we find that Elicit Systematic Review provides screening and extraction accuracy rivaling humans at a fraction of the cost and labor, ushering in a new era in evidence synthesis.
In this post, we dive into our evaluation methods and results. In short, we compared Elicit’s screening recommendations to published systematic reviews and found that Elicit correctly screens in 94% of papers. We (and independent teams) also compared Elicit's extractions against manual extractions and found that Elicit extracts data with 94-99% accuracy.
1) Screening performance
Methodology
We expect researchers using Elicit Systematic Review to start with their own collection of article PDFs identified from other sources (and then augment that collection with Elicit’s search). They can then use Elicit’s Screening step to generate screening recommendations, backed by explanations. This can reduce the amount of time needed to screen thousands of papers from weeks to minutes.

We assessed the quality of Elicit’s screening recommendations by comparing them to the screening decisions made in published systematic reviews.
We compiled a dataset of 58 published systematic reviews, including articles such as:
- Lithium in bipolar depression: a review of the evidence (Riedinger et al. 2023)
- Cost-effectiveness of social media advertising as a recruitment tool: A systematic review and meta-analysis (Tsaltskan et al. 2023)
- Music therapy for improving mental health problems of offenders in correctional settings: systematic review and meta-analysis (Chen et al. 2016)
We extracted the main research question from each review to input as a query into Elicit. For example, we extracted “How effective is lithium in treating bipolar depression in adult patients?” from Riedinger et al. 2023.
For each review, we also asked a large language model to identify which papers the review screened in. Through this, we created a set of “relevant papers” to evaluate Elicit’s recall. Though we verified that all extracted studies were actually screened into their respective review, we did not comprehensively extract all studies from each review. We do not expect this to bias results, given that our screening algorithm uses different technology than the LLM extraction algorithm used here.

Example PRISMA diagram from one of the systematic reviews we used (Riedinger et al. 2023). The positives in our dataset correspond to the 15 included ones at the bottom.
A good screening engine should also effectively screen out irrelevant papers. To simulate a set of “irrelevant papers” that could be found in a database search, we submitted the 58 queries we extracted in the previous step to Consensus, a popular academic semantic search engine. We added all papers found with this method as irrelevant papers to our dataset, except those that seemed too relevant (since that could bias the results) according to an LLM.
Results
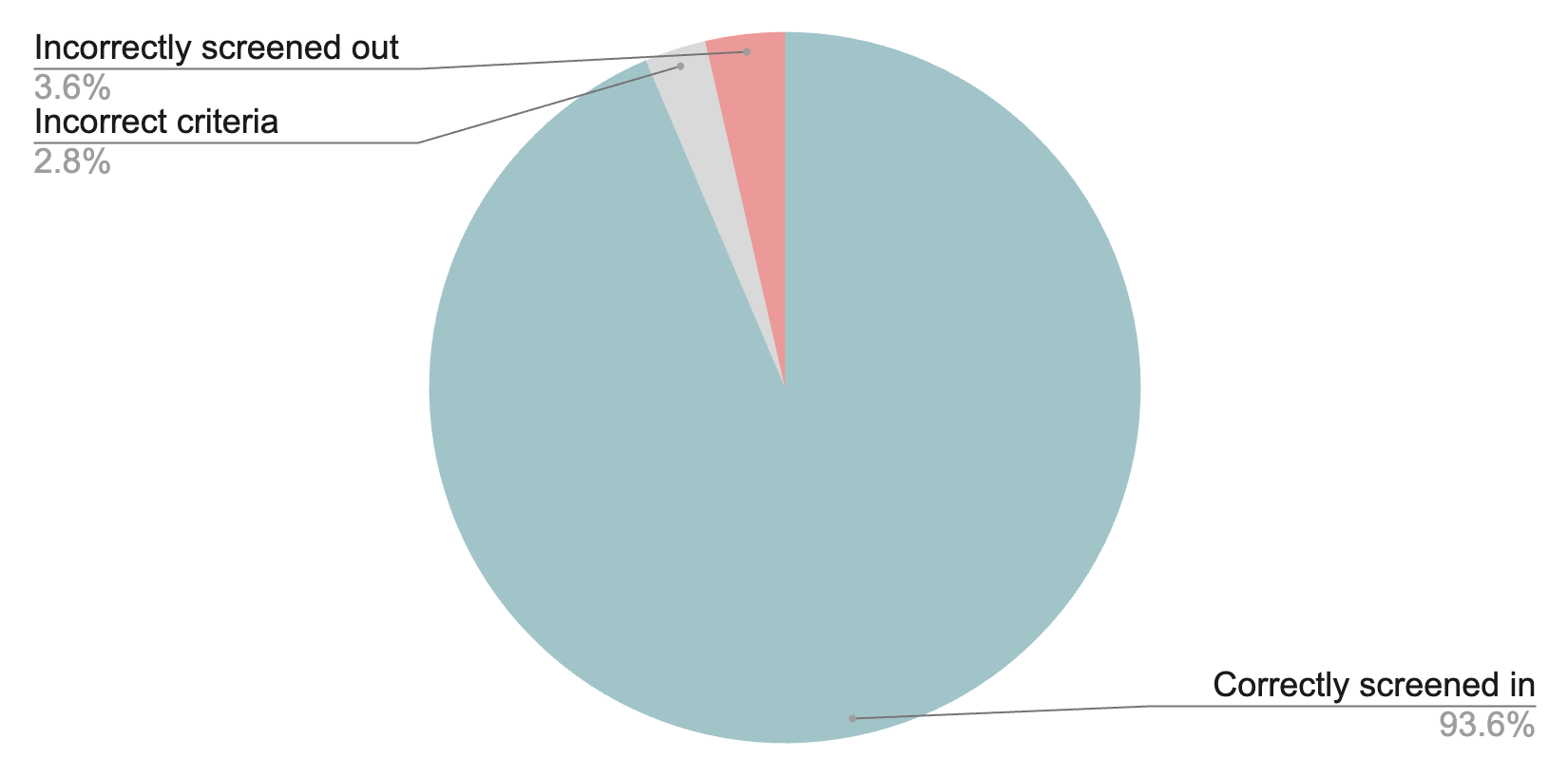
Given this reference set of “relevant papers” and “irrelevant papers”, Elicit:
- Screened in 93.6% of relevant papers (recall/sensitivity)
- Screened out 62.8% of irrelevant papers (specificity/true negative rate)
Recall is the most important metric for title and abstract screening, since excluding relevant papers biases results, which is why we built Elicit to excel on this metric.
We also found that half of the time Elicit improperly screened out papers (thus lowering recall), it was due to improperly generated screening criteria. In practice, systematic reviewers will likely carefully vet Elicit’s screening criteria before screening. Thus, Elicit’s real-world screening recall, given correctly specified criteria, is ~96.4%.
Since Elicit is transparent and editable by design, users can always inspect screening results and override any screening decision.
2) Extraction performance
Data extraction is the most laborious and expensive step in systematic reviews, often requiring months of manual effort. Professional researchers are now using Elicit to extract data in 90% less time, enabling them to conduct larger reviews or repurpose their time for deeper per-paper analysis.

We assessed the accuracy of Elicit’s extractions through both internal and external evaluations.
Internal LLM-based evaluation
Our internal evaluation consists of using LLMs to evaluate how well an Elicit extraction compares against manual “gold standard” extractions. While counter-intuitive, we have previously shown that verifying extractions with LLMs has 89% agreement with manual verification.
Our gold standards consist of 128 thoroughly vetted answers to the predefined extraction columns in Elicit, such as “Participant count” or “Study design,” for a given set of papers. The extraction columns generated in Elicit Systematic Review are not identical but generally similar to those predefined questions. Our evaluation method asks an LLM whether the answer generated by Elicit matches the gold standard as well as the text of the paper — we previously found that giving the LLM both a gold standard and the full text provides more trustworthy results than using either in isolation.
According to this automated evaluation, Elicit’s data extraction is 94% accurate.
External evaluations
Other organizations have independently analyzed Elicit’s performance with minimal or no influence from our evaluation team.
VDI/VDE
The German consulting firm VDI/VDE advises governments and the private sector on innovation and technology. They recently used Elicit to scale up a systematic review on educational interventions from 50 to 550 papers. They checked Elicit’s results vs. expert manual extraction and found Elicit was 99.4% accurate.

They estimated that Elicit allows them to evaluate 11x more papers per project. Read more in our VDI/VDE case study.
CSIRO
A team led by Scott Spillias at CSIRO, Australia's national science agency, evaluated Elicit in a preprint research article released in August 2024.
They compared 3 AI approaches (Elicit, 1 call to GPT-4-Turbo, multiple calls to GPT-4-Turbo) to a human baseline on data extraction for a review about managing fisheries.
Elicit had a near-zero rate of false negatives, meaning it did not miss any key information. “Elicit consistently provided higher quality responses compared to our implementations based on GPT4-Turbo, and also had a negligible false negative rate.”

The team also found that the quality of extractions sometimes outperformed human extractors, “often with more detail or specificity than the human extractor. This included instances where the human extractor missed certain details, for instance, failing to report all the countries mentioned in a paper, which the AI correctly identified.”
Evaluation of reports
After data extraction, Elicit helps researchers start writing their systematic review by analyzing the data and producing a research report. We previously asked researcher specialists to evaluate reports and found that they are more accurate and save more time compared to competitors.
Conclusion
Through internal and external evaluations, we find that Elicit is the most rigorous AI systematic review tool available, providing screening and extraction accuracy rivaling humans at a fraction of the cost and labor.
To further assess Elicit’s Systematic Review, we have separately asked professional researcher evaluators to replicate existing, published reviews using Elicit. We’re excited to share results soon.
Try Elicit Systematic Review
Conduct systematic reviews in 80% less time, without compromising accuracy
Start a Systematic Review