From grep to SPLADE: a journey through semantic search
Almost every app needs search. If you’ve attempted to implement it in your app, you may have discovered that what seems simple on the surface is a deeply challenging technical problem that has kept the brightest minds in computer science busy for decades.
In recent years, machine learning has given us semantic search, vastly improving the capability of search. However, the black-box nature of these tools can make them unsuited for some domains, like academic literature review. How can those domains take advantage of better search, while still having reproducible results?
This article will take you on a journey to understanding search, including the capabilities and weaknesses of the state of the art in semantic search.
The olden days: string matching and full-text search
A simple string comparison like the unix tool grep is the obvious and naive way to implement search. Of course, we quickly see that it doesn’t get anywhere near the results that users want. It may produce false positives like “car” matching “scar,” and false negatives like “goose” not matching “geese.” It also isn’t fast enough once you have a decently-sized corpus of data to search across.
Full-text search has been the gold standard for decades, with powerful capabilities for this built into databases like Postgres. Full-text search uses complex heuristics for better matching (such as pluralization) and indexing to keep search fast in large datasets. Elastic built a $10 billion company on the foundation of full-text search.
This remained the state of the art for almost all apps until the arrival of general-purpose ML-powered search.
Embeddings and latent space
An early idea of mathematically representing words as their underlying concepts goes back as far as the 1950s. Semantic search, as this is now known, focuses on searching for ideas rather than words. Major milestones include Word2vec (2013) and Google’s BERT (2018).
Semantic search works by turning the user’s search query from text into a high-dimensional vector, basically just several hundred numbers in an array. This words-to-vector conversion is known as an embedding, and the conceptual search space the vector implies is called the latent space.
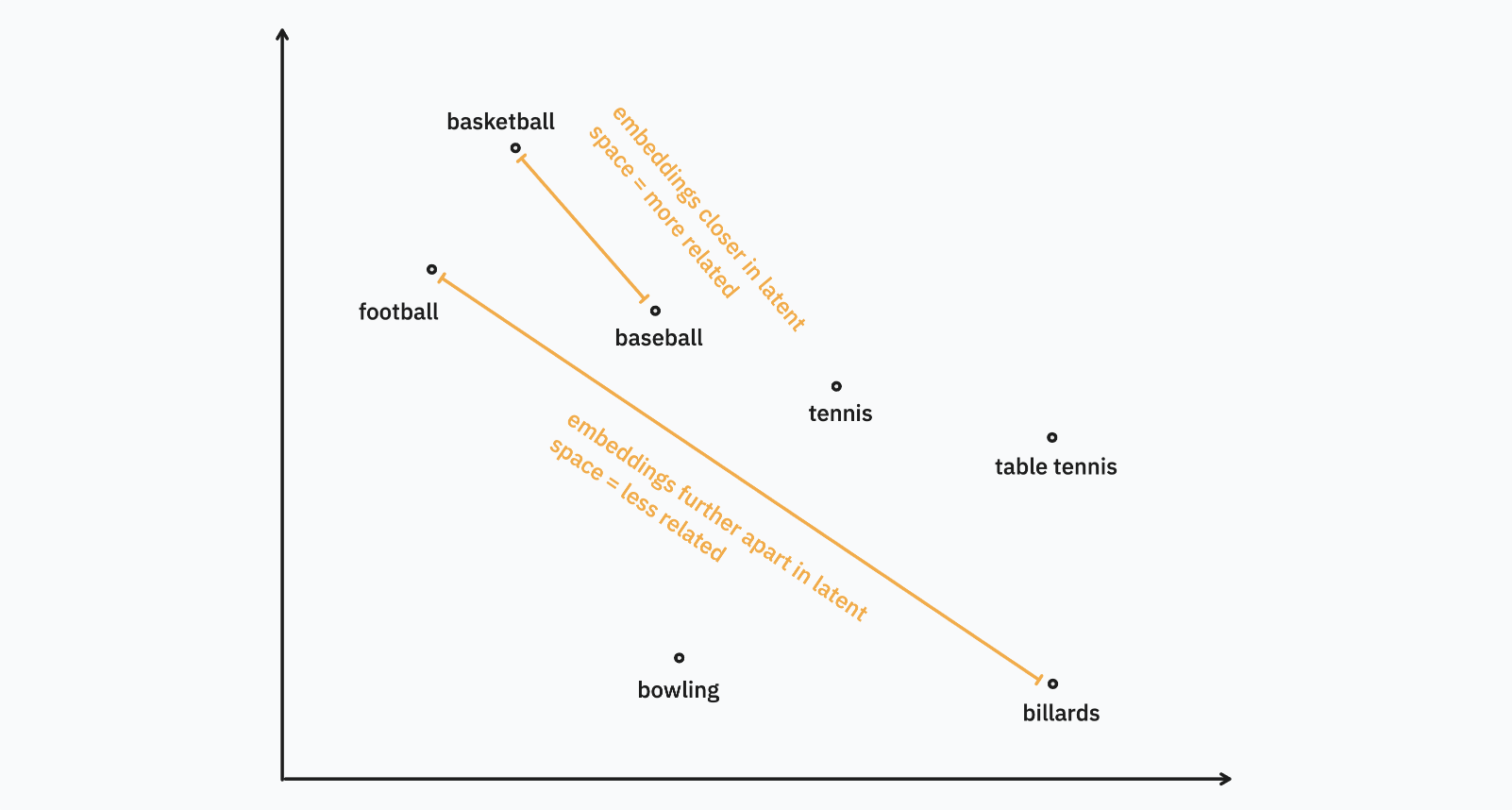
This means that the text “flower” and the text “dandelion”, once encoded this way, will result in vectors that are fairly similar. These can be understood as near each other in the latent space, with distance between them computed in the same way you would compute distance between two points on a geographical map.
So far, we’ve only talked about embeddings for single words. What about more complex phrases?
We could simply calculate the embeddings for each individual term and take the average, but unfortunately this doesn’t work for natural language. For example, the phrases “chocolate is tastier than liver” and “liver is tastier than chocolate” mean completely opposite things, but—in our naïve averaging scheme—would have the exact same embedding.
To handle the nuanced and messy semantics of natural language, we need a more powerful tool.This is where large language models come into play. Rather than processing each word independently, the text is split into chunks and fed as a sequence into the LLM, allowing the model to perceive the richer semantics woven into our languages. The end result is still an embedding, but it’s one which better captures the meaning of the input.
Despite being a relatively new and incredibly powerful tool, the generation of high-quality embeddings has quickly become commoditized. For example, using OpenAI’s embeddings API you can easily add Google-quality search to your app. Simply feed each document in your search corpus into the API to generate an embedding for that document, and do the same for any search query your user provides. Then for each document embedding, calculate the similarity between the query and the document and return the set of documents as your search result.
Semantic search is not ideal for literature search
Semantic search works well in many cases, but it has some shortcomings:
- The nature of most embedding models (and efficient dense vector search algorithms) means that—if you’re not careful—the same query could produce different results between runs.
- It’s a black box. End users don’t understand how the results are ranked. Even ML researchers consider the process a “gray box”: we know the models work but can’t give a great description as to how or why.
At Elicit, we’re building a tool for systematic literature review. The first step in that review is a search that looks similar to what you would see in Google Scholar. The shortcomings of semantic search are acceptable for consumer web search, but less so in the domain literature review. Why?
When academics want to use a search as part of a systematic review or meta-analysis, they need to be able to explain how they got the papers they included. They need to know that it was comprehensive: they haven’t missed any important papers. And others need to be able to reproduce their work.
Other domains might have similar needs and find web-style semantic short too limiting. For example, attorneys or judges search for relevant case law—leaving out important precedent could be disastrous. Even the more common case of searching your own email (where you expect comprehensive, repeatable searches) struggles with semantic search, as the creator of GMail described in their attempts to use Google’s web search infrastructure for their private email search.
So what else can we do?
Query expansion
One folk practice of systematic reviewers is to manually create a huge fanout of search terms. This makes sure every possible permutation is included.

Query expansion, then, is just automating this process. A generic language model can be prompted to specify all the variations on each search term, and those can be fed into a regular full-text search.
This method is transparent and understandable, as the intermediate step is directly legible to humans. The downside is that it’s slow, and the search results are generally still much worse than a vector search.
SPLADE
That brings us to the method that Elicit is working on today: Sparse Lexical and Expansion model, aka SPLADE.
SPLADE is similar to query expansion—in that the user’s query is enriched with synonymous or related terms—but rather than this expansion being a manual process, we instead lean on language models to suggest additional search terms.
One way to think about this is that the language model has already built up a high-dimensional map of how terms are related to each other: this is the latent space of embeddings we described above. Using this map, we can automatically find terms semantically-associated with the user query, and enrich the query with those model-suggested terms. Those are then fed into a regular full-text search.
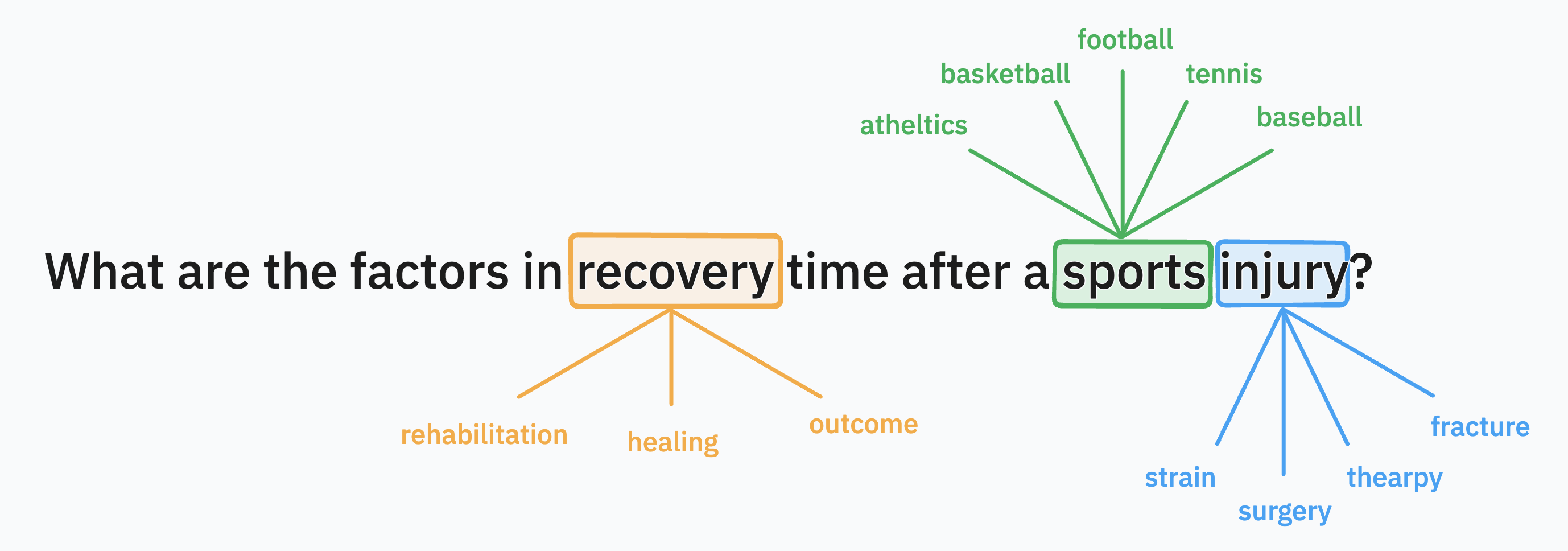
The result:
- It’s deterministic, for a given SPLADE model.
- It’s transparent. Like manual query expansion, SPLADE adds additional language model tokens (conceptually very similar to human-readable search terms) to the query which can be viewed and double-checked by the user if they wish.
- It’s obviously faster, more accurate, and requires less human effort than manual expansion.
So the SPLADE path is fast and close to semantic search quality, while still giving us the reproducibility and transparency that literature search users demand.
As a bonus, we can also train a custom SPLADE model on the particular domain we’re operating in. That means the query expansion would be smarter about, for example, particular jargon used within a domain like athletics, biomedicine, or law.
One more thing: automated comprehensive search
As a thought experiment, imagine you had infinite research assistants. How would you search for relevant papers?
You wouldn’t limit yourself to keyword matches! Instead you might instruct your infinite labor pool read and understand every single paper and check whether or not they are relevant to your query. Indeed, there is a step in systematic review called screening, which is the “tedious but vital first step to synthesize the extant literature”.
Automated Comprehensive Search (ACS) is an attempt to do this with a language model. Although it would be cost-prohibitive to have the language model actually read everything, our friends at Undermind used a clever trick: use semantic search to sort papers by relevancy, and have the language model “read” them in that order. As it proceeds, each paper will become less and less relevant. Model this curve and you can probabilistically guarantee you’ve found everything relevant.
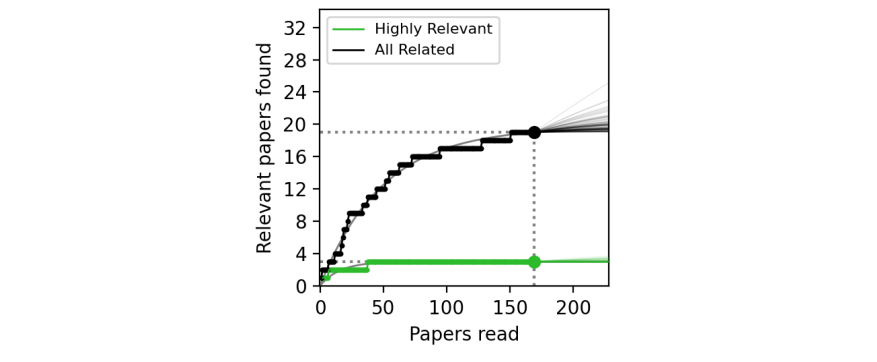
The relevancy score doesn’t need to be perfect: as you go, you can recalculate the scores based on your fine-grained judgments and follow citation trails. This isn’t as reproducible as the SPLADE method described previously, but the exhaustiveness means that matters less. You can state exactly what papers were included, excluded, and on what basis across your entire search space.
There are downsides to this method: it requires including more data for people to analyze, and at the moment it’s very slow and expensive. But the upsides are that it avoids many issues with search bias, and we expect the cost to come down in time.
Conclusion
Semantic search uses ideas instead of words, which makes it a huge step forward from traditional full-text search. But it still has weaknesses in many domains that require transparency and reproducibility. At Elicit we’re continuing to use the latest developments in thinking on semantic search technologies to give our customers the results they’re looking for. Come join us if this sort of problem is interesting to you.