Against RL: The Case for System 2 Learning
People are excited about Deepseek R1 (and O1 and O3). It seems like RL might finally be starting to actually work for LLMs, not just the weak approximation that is RLHF.
But for building safe superintelligent systems, RL is at best an intermediate step, and at worst an incredibly unsafe dead end. Why? Because RL is System 1 learning, i.e. learning based on fast, intuitive updates.
For building systems that can reliably operate over long time horizons and improve through interaction with the world, what you eventually need is System 2 learning - training mechanisms that deliberately reflect on what kinds of belief updates are licensed by the data.
This shouldn’t come as a surprise - at inference time we’re already using extensive System 2 techniques, and this is what enables R1 and the likes to have such good performance. If they had to reply in one token without chain of thought, they’d be terrible at any benchmark we care about.
But what is System 2 learning? The puzzle, in one picture:
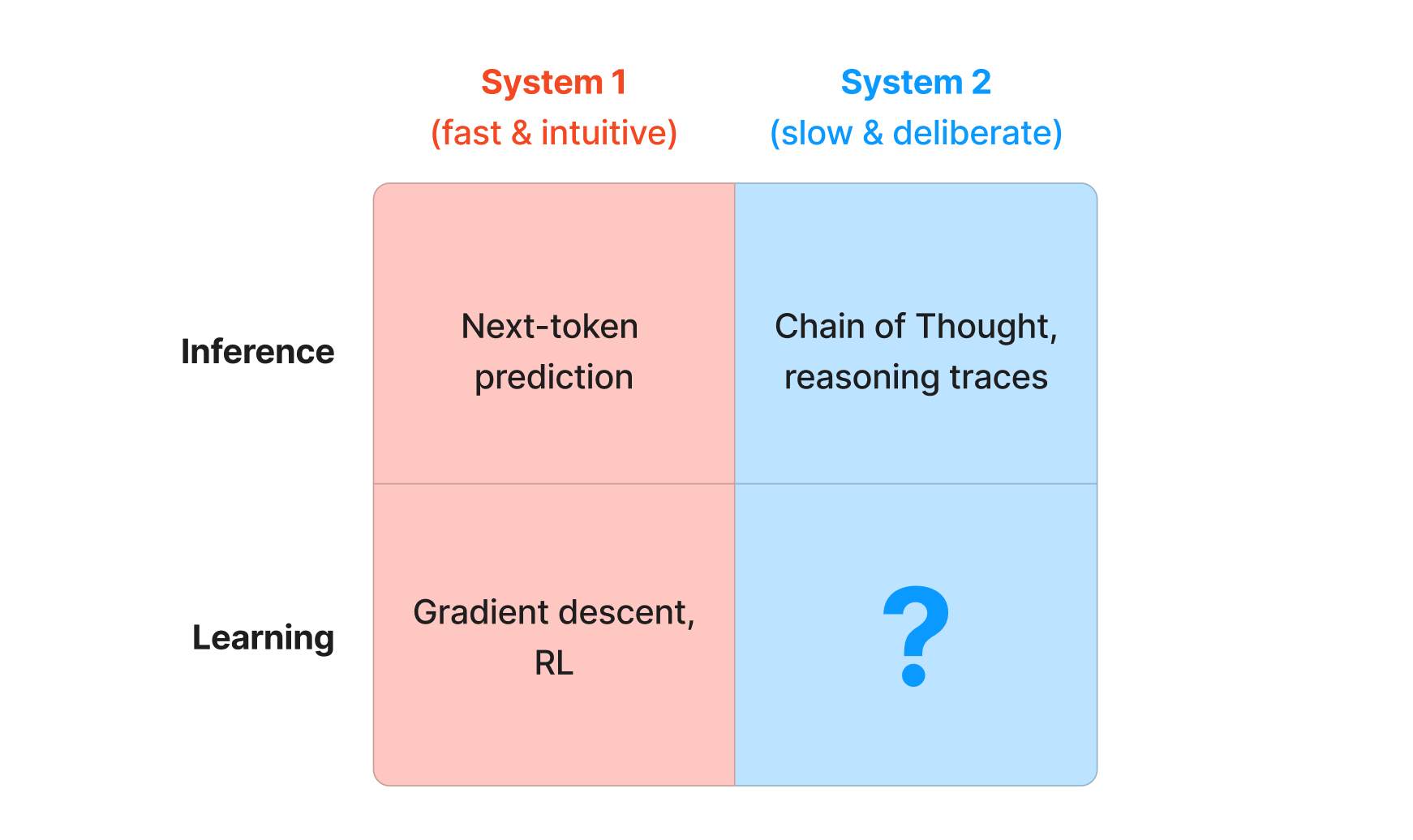
The story so far
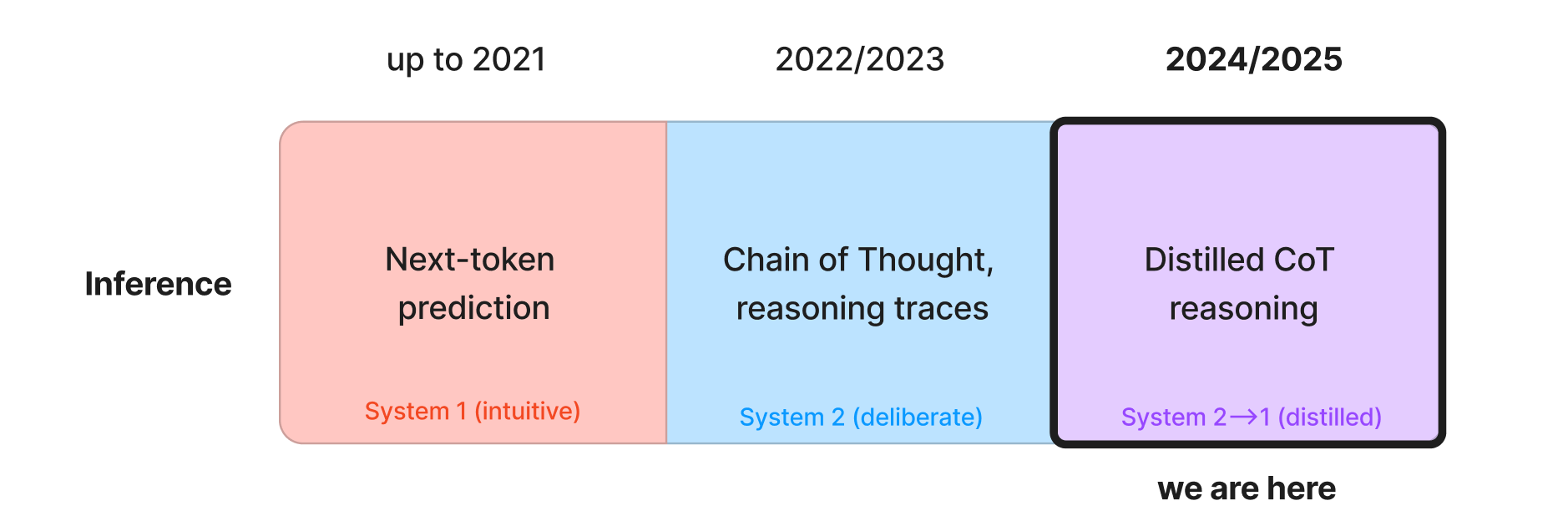
How we use LLMs at inference time has radically changed since GPT-2—we’ve moved from next-token predictors that more or less immediately try and solve a problem (System 1) to chain of thought (“Let’s think step by step”, basic System 2) and more recently to distilling the outputs of System 2 thinking back into fast System 1 models:
But arguably training has changed much less:
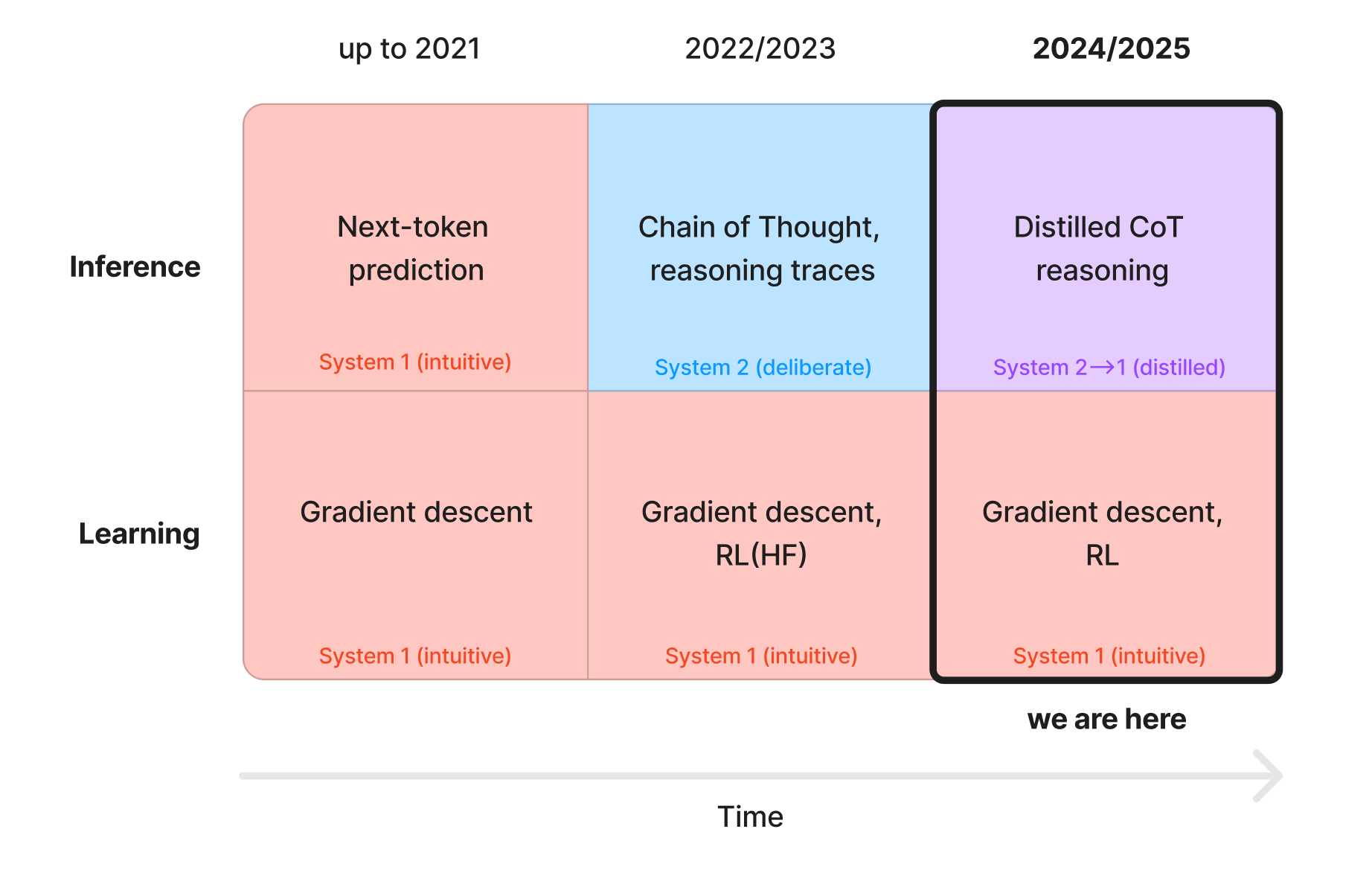
Yes, the data that goes into the gradient updates is different, and we’re smarter about how we produce it (from raw pretraining to instruction following to RLHF to RL for code/math), and the base models are larger, but how that learning happens isn’t fundamentally different.
Learning at training time is still a System 1 process, which means:
- The relation between each datapoint and the update is fixed, simple
- We extract little signal from each data point, and so are very data-inefficient
- The process is hard to align, suffers from reward hacking and sycophancy
Still, the data that goes into this training process has improved a lot and will improve further - RL has many wins left.
RL will succeed before it fails
RLHF / RLAIF still plays a major role for training most models and it’s barely RL. Karpathy:
Reinforcement Learning from Human Feedback (RLHF) is the third (and last) major stage of training an LLM, after pretraining and supervised finetuning (SFT). My rant on RLHF is that it is just barely RL, in a way that I think is not too widely appreciated. RL is powerful. RLHF is not. Let's take a look at the example of AlphaGo. AlphaGo was trained with actual RL. The computer played games of Go and trained on rollouts that maximized the reward function (winning the game), eventually surpassing the best human players at Go. AlphaGo was not trained with RLHF. If it were, it would not have worked nearly as well.
This will change - we haven’t seen Move 37 for LLMs yet—haven’t seen true creativity that surprises us because it’s so different from what we would have thought of, and better. o1, o3, and Deepseek R1 bring us one step closer.
The RL techniques used for training LLMs are extremely basic right now, closer to REINFORCE than to the sort of RL with a learned model that made AlphaZero impressive. AlphaZero is compressing millions of long-term rollouts into each gradient step; these are big updates, not tiny local tweaks, perhaps halfway between System 1 and System 2 learning.
People will predictably be amazed and shocked when this starts working for LLMs.
And yet, it’s not the right way to structure learning for potentially superintelligent systems. It may be a useful limited tool, in the same way that matrix multiplication is a useful limited tool, but it shouldn’t be the level of abstraction on which we think about learning dynamics.
Let’s see how it fails and what it would mean to do better.
How RL fails
Data inefficient
It’s extremely data inefficient. This matters less when you can perfectly simulate your environment (as is the case for math problems, programming puzzles, and some computer tasks), but matters a lot when you have to gather empirical evidence.
An intuition pump: I'm launching a new feature for Elicit. It fails to get much uptake. I do error analysis - where did things go wrong? Did we not implement it well? Did users not want it in the first place? Bad UX? Ah, no, we derisked that by running user tests on a prototype. Maybe performance dropped in production relative to testing? What could have led to that? How can I change my planning to prevent that from happening in the future? I learn so much from this one case, and maybe more importantly, I know what updates not to make. This is what AI learning should be like.
In the long run, this could differentially disadvantage integrating feedback on our values and what it means to be corrigible relative to feedback about which plans work out in simulated or otherwise fast-feedback environments. (But maybe not - maybe the accuracy of simulations will catch up in time.)
Not transparent
By default, RL pushes away from transparency. From the R1 paper:
Drawback of DeepSeek-R1-Zero Although DeepSeek-R1-Zero exhibits strong reasoning capabilities and autonomously develops unexpected and powerful reasoning behaviors, it faces several issues. For instance, DeepSeek-R1-Zero struggles with challenges like poor readability, and language mixing.
This will likely get worse. Karpathy again:
Weird as it sounds, it's plausible that LLMs can discover better ways of thinking, of solving problems, of connecting ideas across disciplines, and do so in a way we will find surprising, puzzling, but creative and brilliant in retrospect. It could get plenty weirder too - it's plausible (even likely, if it's done well) that the optimization invents its own language that is inscrutable to us, but that is more efficient or effective at problem solving. The weirdness of reinforcement learning is in principle unbounded.
Of course, you can always just give up entirely and train models to reason in latent space.
Misaligned
Most critically, the blind search over models by default leads to reward hacking and misalignment. If we get to strong reasoning & planning through RL, this could be catastrophic. Roger Grosse made this diagram which shows the dynamics (I flagged the current point in time):
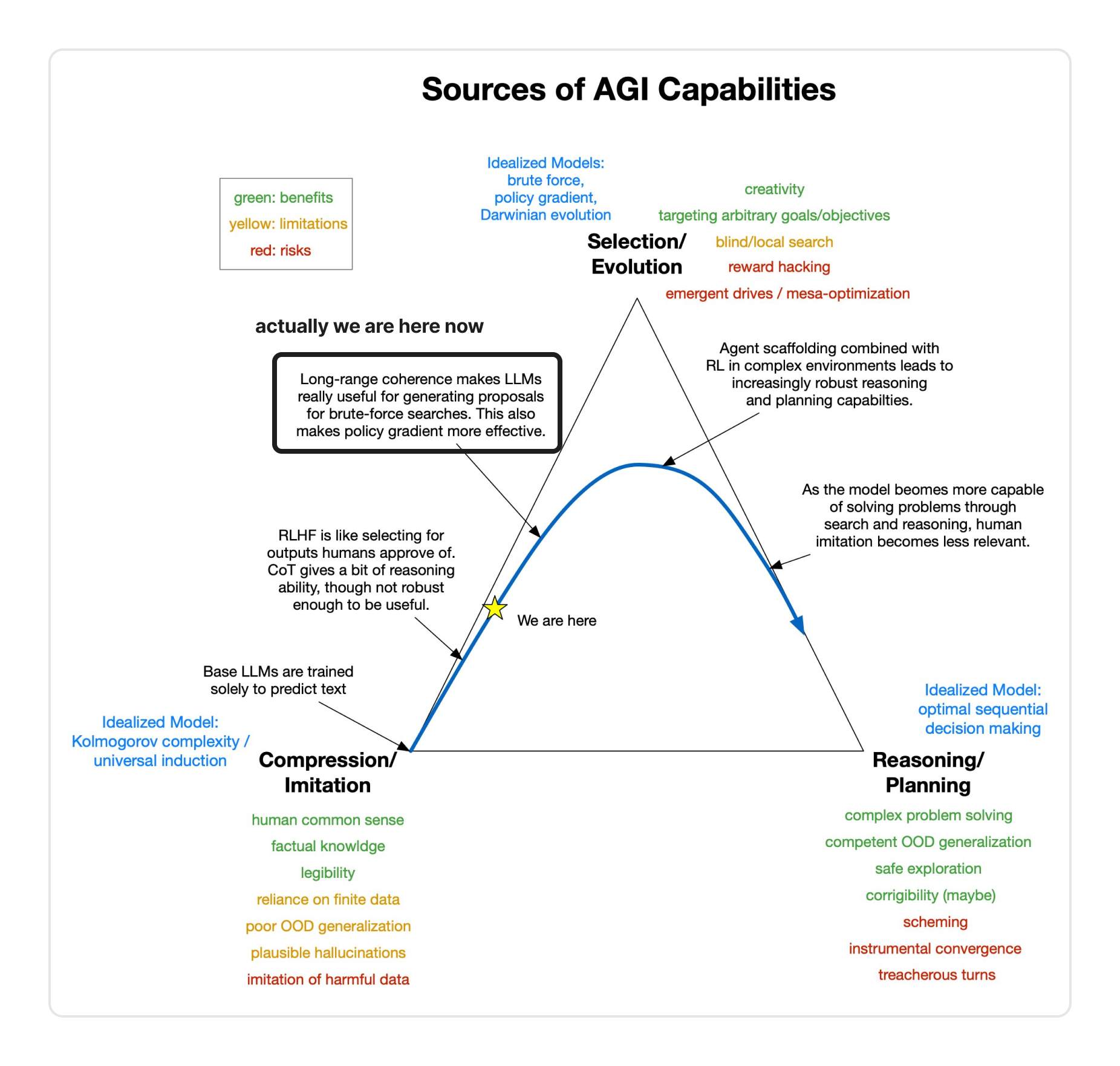
This is the most important of the failure modes—even if believe that RL can be made data-efficient and transparent, we're still reliant on something like AI control if we can't guarantee alignment.
So the question is—how do we get from compression/imitation (bottom left) to reasoning/planning (bottom right) without passing through strong selection/evolution (RL)? In other words, how do we get to deliberate System 2 learning with minimal reliance on System 1 learning?
Towards System 2 Learning
So, we’re back to the original puzzle—what is the System 2 equivalent for learning?
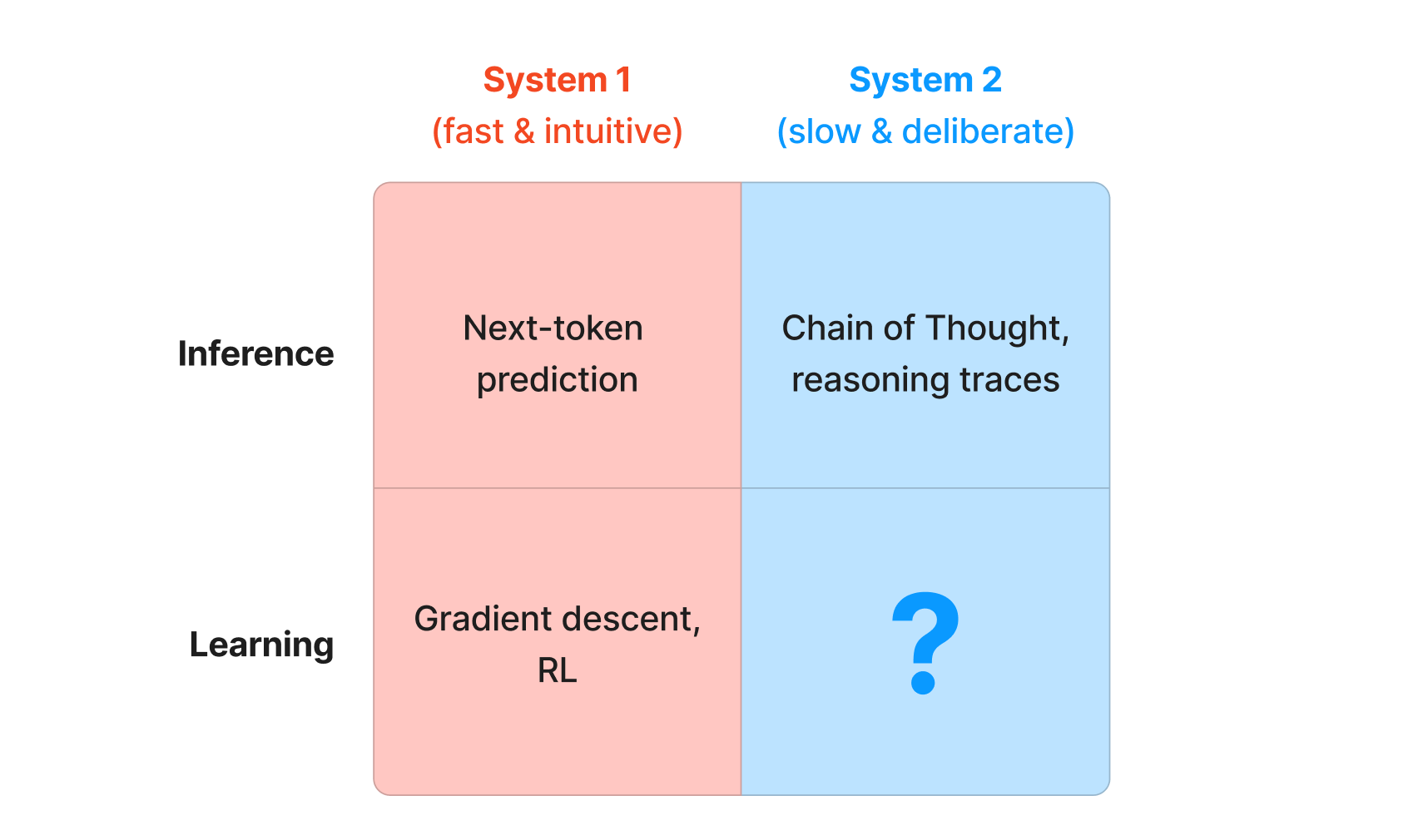
A few things are clear:
- Obviously the Bitter Lesson is relevant here. Any approach that doesn’t have a story for how it turns more compute into better answers is immediately out.
- Likewise, if there isn’t a story for how we can find delightfully unexpected answers like Move 37 it’s not a candidate.
- If the entire knowledge state is represented in opaque matrices, getting models to deliberately reason about how it should be changed will be tough; maybe it can be done through layers of indirection, constrained updates, and clever meta-learning, but it will definitely make the story harder. On the other hand, the more transparent world models are part of the story, the more it gets easier (Elicit lab meeting; also see Bengio's agenda).
My guess is that this will take a significant rethinking of how we train, deploy, and use LLMs. One approach here is to zoom out from “what is the language model learning” to “what is the system that contains the language model learning”; the system can learn even if component models are static. Fortunately, some progress along these lines will happen anyway as people think through agent architectures & related scaffolding.
Right now, the ambitions of folks in this area are rather mild, and the quality & amount of thinking that goes into progress feels less targeted than what I’m seeing for scaling up RL. As the stakes become more obvious I can see this changing.
If we get this architectural shift right, the future of learning will look more like the history of inference:
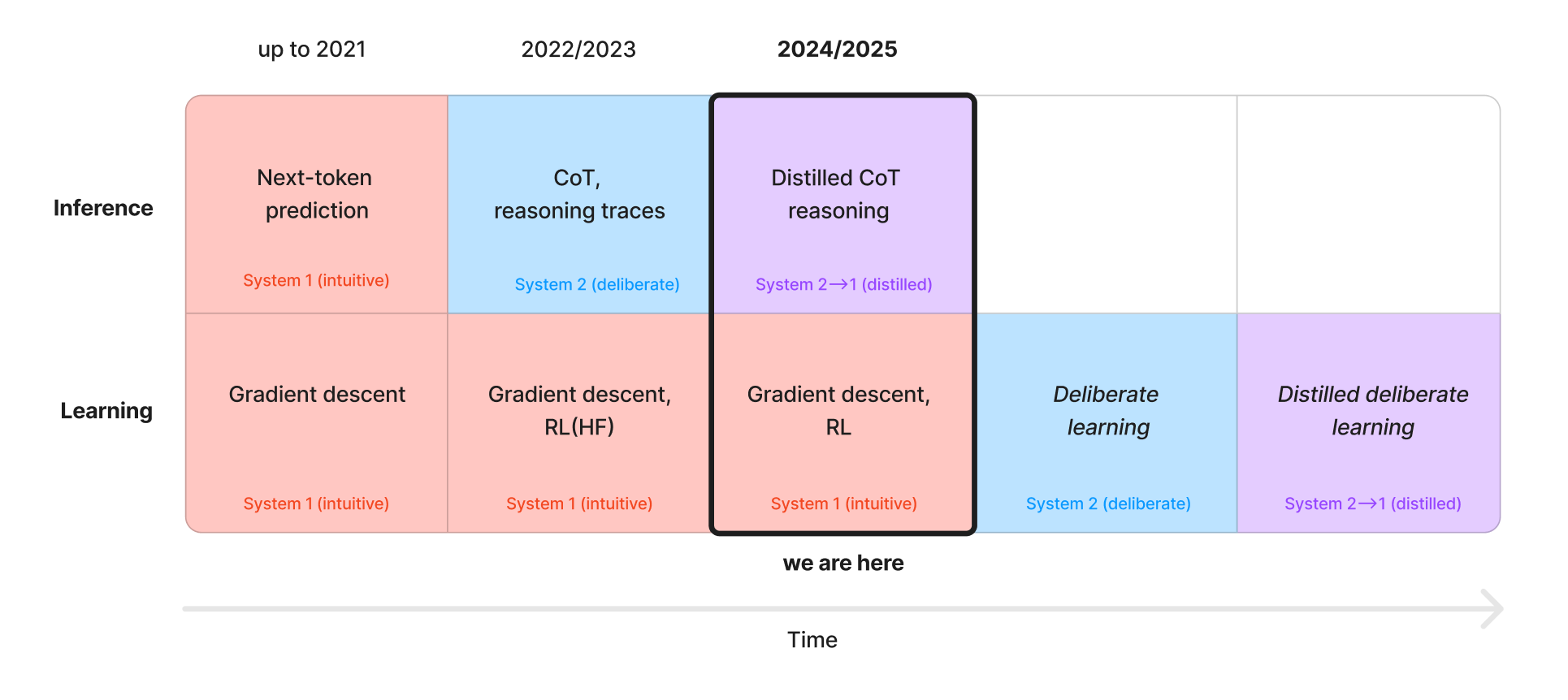
Once we figure out how to do systematic, controllable System 2 updates from data, we’ll likely still want to speed it up, similar to how a lot of the chain-of-thought work eventually gets sped up and distilled into much smaller models. But in terms of safety, this is a much better situation to be in than pure System 1 learning.
Join us at Elicit to build a System 2 learner for scientific reasoning and high-stakes decision-making. We have a research residency and other open roles.
Thanks to Owain Evans, Owen Cotton-Barratt, James Brady, Charlie George, and Jungwon Byun for helpful comments; Y for design help; and Tom Schaul for insightful discussion.