Factored Verification: Detecting and reducing hallucinations in frontier models using AI supervision
We evaluate a simple automated method for detecting hallucinations in abstractive summaries of academic papers
At Elicit, we want to help researchers derive new insights from existing literature and scale up good reasoning. To achieve this, Elicit uses a range of different large language models to automate the search, extraction and summarization of academic literature. Language models, while extraordinarily powerful, aren't trained to be truth-seeking and are prone to generating false claims about a given source text (i.e hallucinating). At best, this causes our users to waste verifying claims made by Elicit or worse update their thinking based on incorrect information.
The main technique to reduce hallucinations involves using reinforcement learning from human feedback (RLHF) to encourage the model to be more truthful. Prior work has already established that this can induce sycophancy and power-seeking behavior. We believe that RLHF is not always aligned with the goal of accurate summarization even in current generation models: GPT-4 already surpasses the performance of the average human on many different academic tasks. The model can summarize highly technical information from multiple documents in seconds. A non-expert does not have sufficient domain knowledge to understand the nuances of the summary and correct subtle mistakes. RLHF could in fact induce the model to generate “good looking” summaries that could, for example, present a compelling narrative around a research question which is unsupported by the literature.
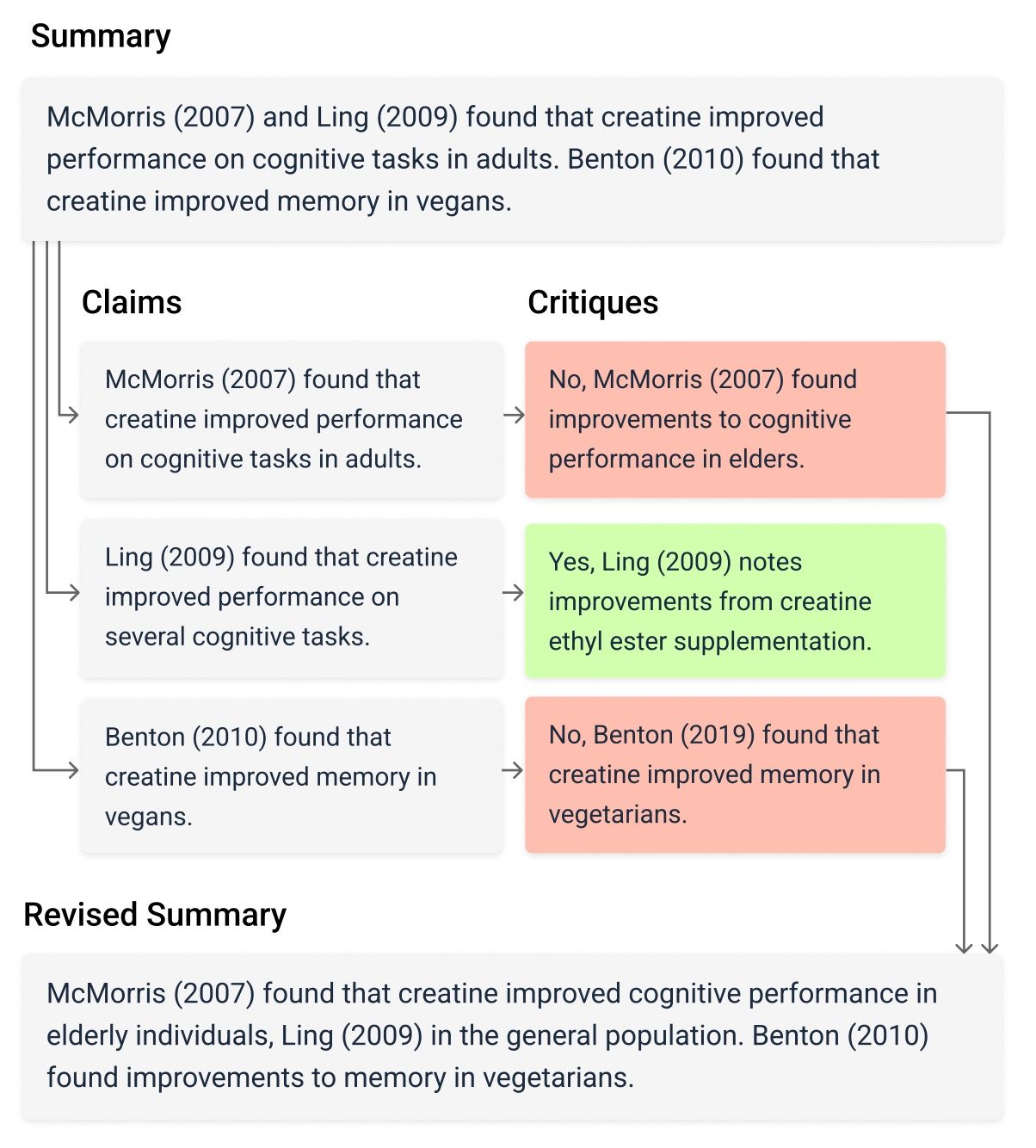
We explore a method we call factored verification to help solve this problem. The technique involves breaking up a summary into smaller pieces (claims, sentences, …) and verifying each one individually. This has 2 advantages:
- First, verifying a single claim is easier for the model to correct than checking an entire summary.
- Second, this narrower task is also easier for humans to check.
This technique can be thought of as an application of factored cognition and inherits the associated safety benefits. This allows the use of weak or weakly aligned models to supervise stronger ones. This also allows the oversight process to scale with model capabilities.
As part of this method, we construct factored critiques by concatenating each false claim and the relevant model reasoning into a single critique. We then ask the model to revise its summary based on this feedback. Importantly, if no errors are found we do not change the summary. This avoids the model “correcting” true statements which is an issue with chain-of-thought-based self-correction. Meta’s concurrent chain-of-verification work can be viewed as the same approach applied to out-of-context hallucination reduction, whereas we focus on in-context hallucination.
Below is an example of a factored critique:

Our main empirical findings are:
- Factored verification achieves SOTA the summarization section of HaluEval beating chain of thought prompting.
- When summarizing across multiple academic papers, we find 0.62 hallucinations in the average ChatGPT (16k) summary, 0.84 for GPT-4, and 1.55 for Claude 2.
- Asking GPT-4 to generate a critique of its summary and then revise it actually increases hallucinations by 37%. This is consistent with the findings in “Large Language Models Cannot Self-Correct Reasoning Yet”.
- We ask models to self-correct using factored critiques and find that this lowers the number of hallucinations by an average of 35% to 0.49 for ChatGPT, 0.46 for GPT-4, and 0.95 for Claude 2.
- In the small sample we validated, humans initially missed over half of the true hallucinations which were only found after inspecting the model's reasoning. At the same time, GPT-4 does overestimate the number of hallucinations by about 50%.
- Similar to prior work, we find that generating critiques works better with stronger models (GPT-4) but generating and revising summaries can be done with weaker ones (ChatGPT).
This project was done as part of our work on internal tools for testing and improving the accuracy of Elicit. We’re excited about a world where progress in AI safety can at least partially be product-driven. It’s clear that human feedback doesn’t scale and can induce unintended negative effects in frontier models. We hope that our work provides some evidence that scalable AI oversight is becoming increasingly feasible.
This work was done by Charlie George and Andreas Stuhlmüller and is published at an upcoming IJCNLP workshop and is live as a preprint on arXiv now.
Join us if you want to advance the truthfulness & reliability of advanced AI systems in the context of a product with 200k+ active users each month.